In 2026, a strange thing is happening across the software industry. Teams that spent years breaking their applications into dozens of microservices are now putting the pieces back together. Not into the old, tangled monoliths of the past but into something cleaner: the modular monolith.
This article is about that shift. We'll walk through modular monolith vs microservices as a real, practical decision not a trend to follow blindly. You'll see why microservices technical debt quietly piles up, why distributed systems complexity costs more than most teams expect, and how reducing cloud infrastructure costs is now driving architecture decisions more than "best practice" slides ever did.
If you're a developer, an engineering lead, or someone using AI coding tools to build and maintain systems, this guide gives you a grounded way to decide what's right for your team backed by real numbers and real company stories, not hype.
Quick-Fix Summary Box
If you only have two minutes, here's the short version:
Situation | Recommended Architecture |
|---|---|
Team under 50 engineers | Modular monolith |
Single codebase, unclear ownership boundaries | Modular monolith with enforced module boundaries |
Need independent scaling for one specific workload (e.g., payments) | Modular monolith + extract that one service |
100+ engineers, multiple independent teams, regulatory isolation needs | Microservices, with strong platform investment |
Already in microservices and drowning in operational cost | Consolidate gradually using the Strangler pattern in reverse |
The core idea: start modular, extract only when evidence — not fashion — demands it.
What Is a Modular Monolith (vs Microservices)?
To understand the modular monolith vs microservices debate, you need clear definitions, because these terms get thrown around loosely.
A monolith is a single application. One codebase, one build, one deployment. Every part of the system runs inside the same process.
Microservices architecture splits an application into many small, independently deployable services. Each service owns a specific business function, say, billing, inventory, or notifications and they talk to each other over a network, usually through APIs or message queues.
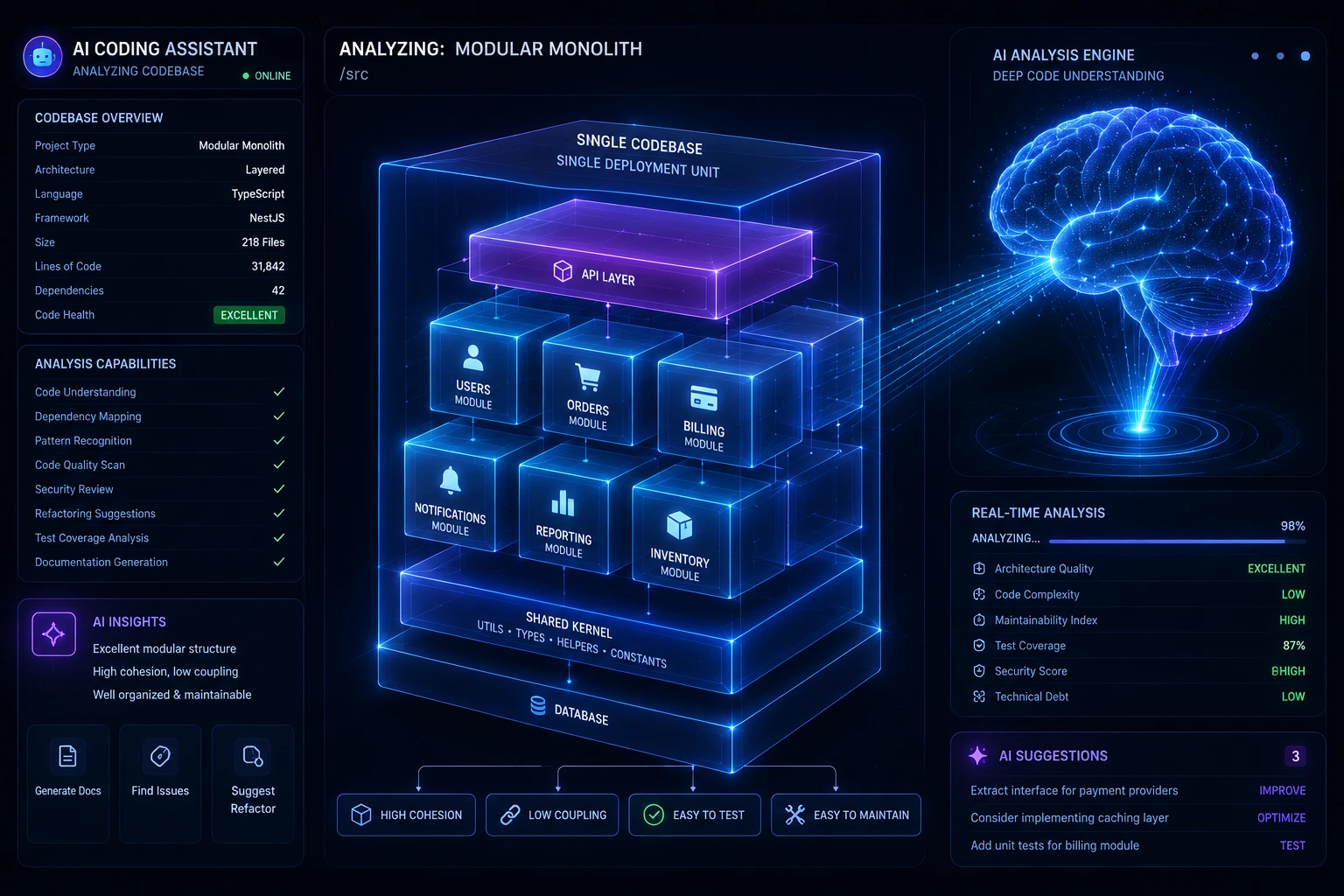
A modular monolith sits between the two. It's still one deployable unit, but internally it's organized into strict modules with clear boundaries. Each module owns its own logic and, often, its own set of database tables. Modules talk to each other through defined interfaces and in-process function calls or an internal event bus never by reaching into each other's internals.
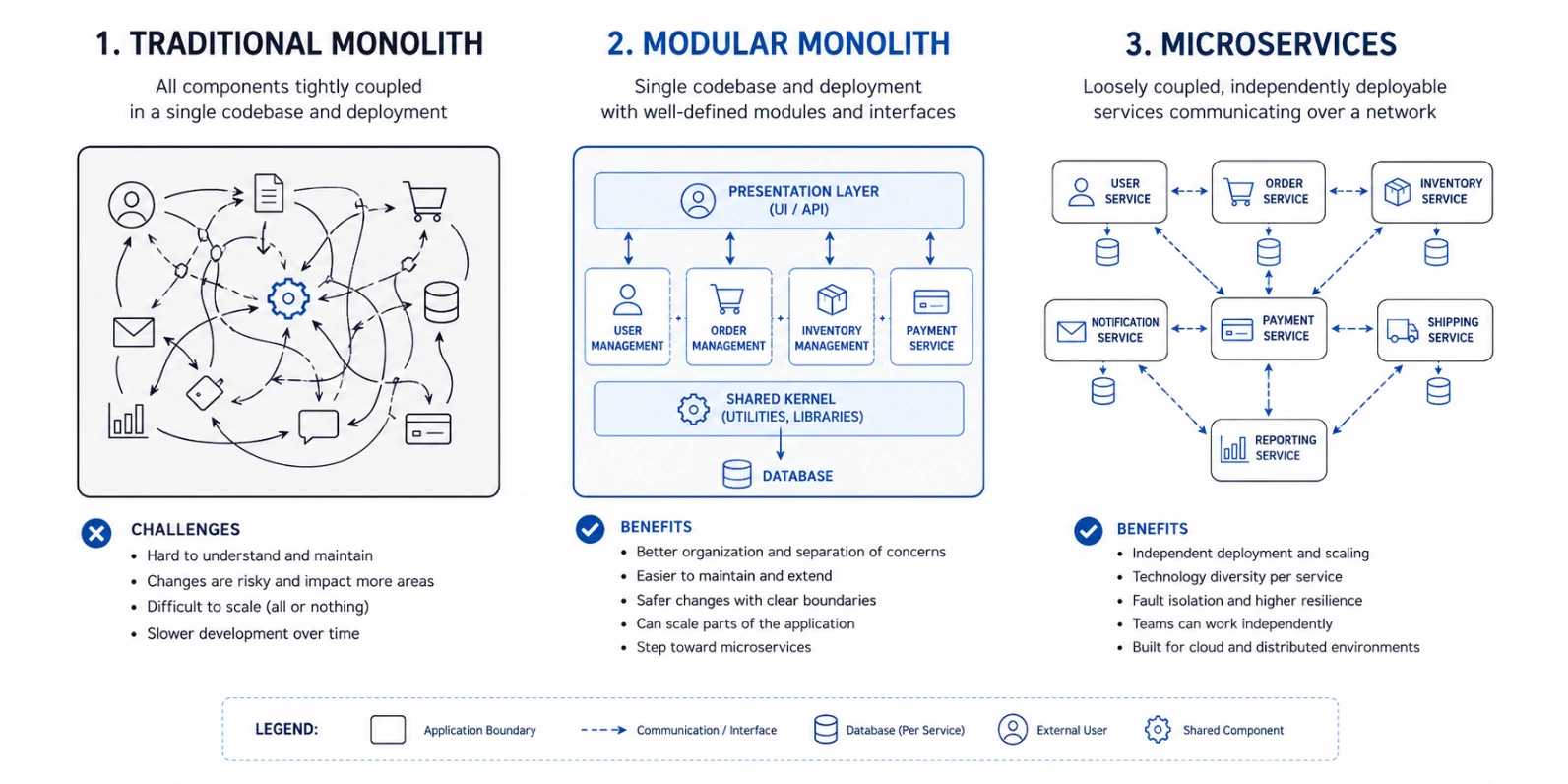
Here's a simple comparison table:
Feature | Traditional Monolith | Modular Monolith | Microservices |
|---|---|---|---|
Deployment units | 1 | 1 | Many |
Module boundaries | Often blurry | Strictly enforced | Enforced by network |
Communication | Direct calls anywhere | Defined interfaces, in-process | Network calls (HTTP/gRPC/queues) |
Database | One shared schema, often messy | Schema-per-module, shared instance | Database-per-service |
Scaling | Whole app scales together | Whole app scales together | Each service scales independently |
Operational overhead | Low | Low | High |
Best for team size | Any | 1–100 engineers | 100+ engineers, multiple teams |
The key insight: a modular monolith gives you many of the organizational benefits people originally wanted from microservices clear ownership, defined interfaces, independent development without paying the operational tax of running a distributed system.
Why Does This Problem Happen?
Why did so many teams adopt microservices in the first place, only to walk it back? The pattern is consistent enough that it's worth naming honestly.
Most teams didn't adopt microservices because they had a measured, scale-driven need. They adopted microservices because it was presented as "the modern way to build software." Conference talks, blog posts, and job postings all pointed the same direction. Teams looked at how Netflix or Amazon ran their systems and assumed the same architecture would work for them without having Netflix's or Amazon's scale, team size, or platform investment.
The result, repeated across thousands of companies: a 10-person team ends up running 30 services, each with its own deployment pipeline, its own monitoring dashboard, and its own way of failing. Every one of those services adds coordination cost. None of them were justified by actual traffic or scaling needs.
This is the heart of the monolith vs microservices architecture debate in 2026: the cost of microservices isn't really about the technology. It's about whether your organization has the operating model to run a distributed system. If it doesn't, you end up building distributed software while still operating like a small team and you get the downsides of both worlds.
It's worth noting that microservices adoption itself is still huge. Gartner has reported that roughly 74% of surveyed organizations currently use microservices architecture, with another 23% planning to. The issue in 2026 isn't that companies are abandoning microservices wholesale; it's that a meaningful share of that population is now right-sizing, consolidating the parts that never needed to be separate. One commonly cited rule of thumb:
microservices start paying for themselves once a team grows past roughly 30 engineers and needs to distribute organizational complexity to keep shipping fast; below that headcount, the coordination overhead usually costs more than it saves.
Common Causes of Microservices Pain
Here are the specific causes that keep showing up when teams explain why they're moving back to a modular monolith.
1. Premature service extraction
Splitting a system into services before there's a clear, data-backed reason to do so. Teams split along guesses about future scale, not actual measured load.
2. Distributed systems complexity
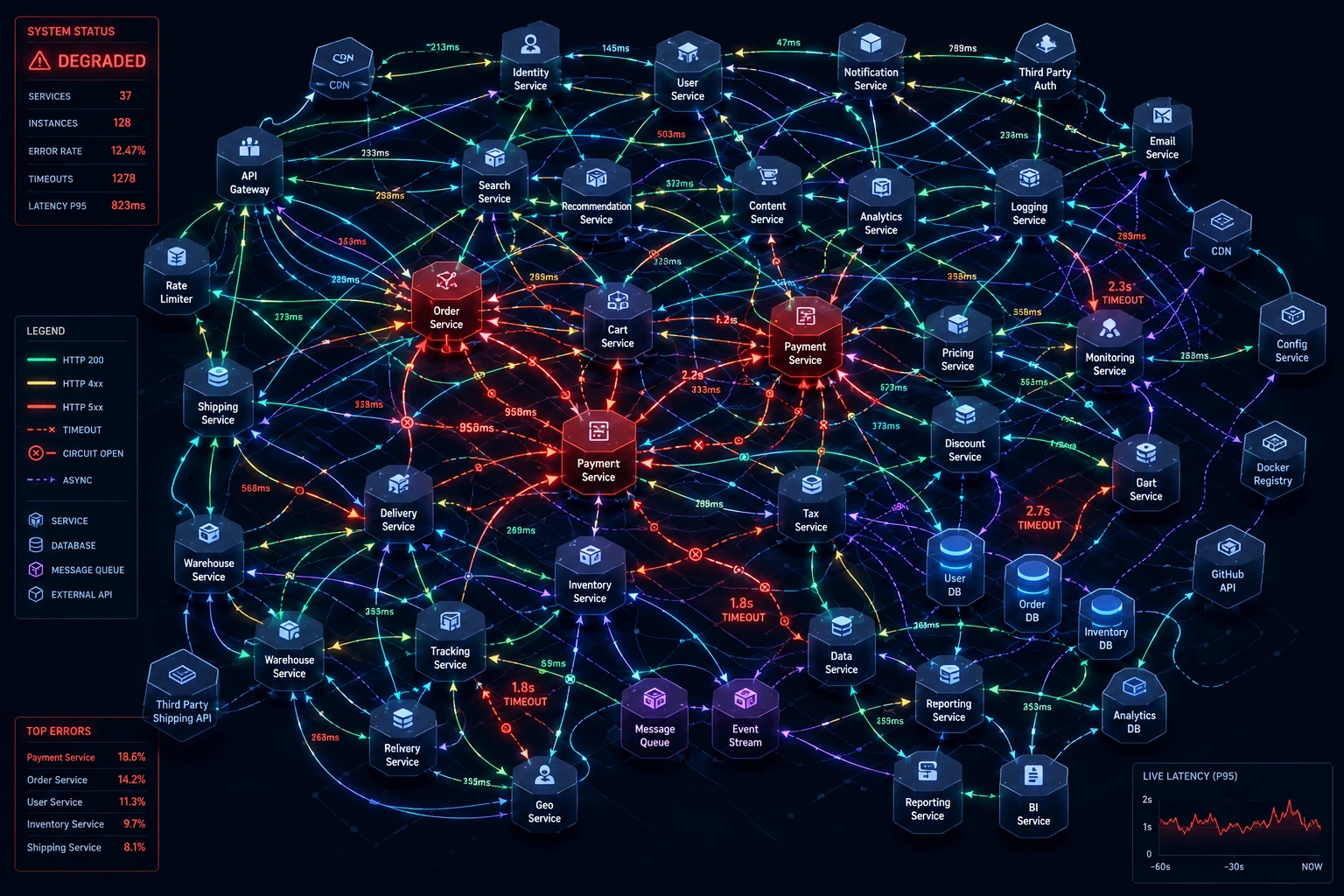
Once logic is spread across services, simple bugs become multi-hour investigations. A single failed payment might require tracing a request across five services, three message queues, and two databases just to find where it broke.
3. Network calls replacing function calls
Every interaction that used to be a fast, in-memory function call becomes a network call with latency, retries, timeouts, and failure modes that didn't exist before.
4. Operational overhead and tooling sprawl
Service mesh, distributed tracing, container orchestration, multiple CI/CD pipelines, secrets management per service all of this needs people to build and maintain it. Most teams under 50 engineers don't have spare platform engineers for this.
5. Data consistency problems
Each service owning its own database sounds clean in theory. In practice, it means no more simple database transactions across related data. Teams end up building complicated workarounds (sagas, eventual consistency, compensating transactions) just to keep data in sync.
6. Microservices technical debt
Ironically, the architecture meant to reduce coupling often creates a new kind of coupling: services that constantly call each other in chains, services that can't be deployed independently because they secretly depend on each other's release timing, and "shared libraries" duplicated and drifting across repos.
7. Rising cloud infrastructure costs
Running 30 small services usually costs more than running one well-optimized application, because of idle compute, duplicate base images, redundant logging/monitoring agents, and inter-service network traffic charges.
8. Conway's Law mismatch
Microservices work best when service boundaries match team boundaries. If your org doesn't have separate, autonomous teams for each domain, you end up with a distributed system run by one team trying to act like ten teams.
Step-by-Step Solutions: Moving to a Modular Monolith
If your team is feeling this pain, here's a practical, step-by-step path back toward a modular monolith without a risky big-bang rewrite.
Step 1: Map your current services and their real traffic
Before touching any code, list every service you run. For each one, record requests per second, CPU/memory usage, and how often it's deployed independently of others. You'll usually find that most services have low, steady traffic and are deployed together anyway — meaning they were never really independent.
Step 2: Identify "fake" microservices
A "fake" microservice is one that's only ever called by one other service, is always deployed in lockstep with it, and has no independent scaling need. These are prime candidates for consolidation.
# Example: identifying tightly-coupled service pairs
# Look for services that are always deployed together in your CI/CD logs
grep "deploy" deploy-logs.txt | sort | uniq -c | sort -rn
Step 3: Define your target modules
Group your services by business domain (orders, billing, inventory, notifications) rather than by technical function. Each domain becomes one module in the new monolith.
Step 4: Build the monolith shell with enforced boundaries
Create one application with folders per module. Each module gets its own:
Public interface (the only way other modules can call into it)
Internal logic and data access code
Database schema (even if it lives in the same physical database)

Example structure in a Node.js/TypeScript project:
src/
modules/
orders/
api.ts // public interface — only this file is imported by other modules
service.ts
repository.ts
billing/
api.ts
service.ts
repository.ts
notifications/
api.ts
service.ts
repository.ts
shared/
eventBus.ts
Step 5: Replace network calls with an internal event bus
Where services used to talk over HTTP or a queue, replace that with in-process function calls or an internal event bus. This removes network latency while keeping modules decoupled.
// Internal event bus example
eventBus.publish('order.created', { orderId, userId });
// In the billing module
eventBus.subscribe('order.created', (event) => {
billingService.createInvoice(event.orderId);
});
Step 6: Enforce boundaries with tooling, not just discipline
Use linting rules or architecture tests so a module can't accidentally import another module's internals.
// Example ESLint rule restricting cross-module imports
{
"rules": {
"import/no-restricted-paths": [
"error",
{
"zones": [
{
"target": "./src/modules/orders",
"from": "./src/modules/billing",
"except": ["./api.ts"]
}
]
}
]
}
}
Step 7: Migrate data gradually
Move database tables under the ownership of the correct module one at a time. You don't need separate database instances, just clear schema-per-module ownership inside a shared database, with rules against cross-module joins.
Step 8: Decommission services gradually
Use a reverse "Strangler" approach: redirect traffic from the old service into the new module, monitor for issues, then retire the old service once traffic is fully migrated.
Step 9: Re-measure your costs and incident metrics
Track cloud spend, deployment frequency, mean time to resolve incidents, and on-call burden before and after. This is the evidence that proves (or disproves) the move.
Advanced Troubleshooting Methods
Sometimes the simple steps above aren't enough, especially in larger or older systems. Here are advanced techniques for trickier situations.
Handling shared databases that have grown messy
If multiple old services have been writing directly into shared tables for years, use a "data ownership audit": for every table, identify exactly one module that will own writes to it going forward. Other modules can read through that module's public interface only.
Untangling circular dependencies between modules
If module A calls module B, and B calls A, this is a sign your domain boundaries are wrong. Extract the shared logic into a third module, or invert the dependency using domain events instead of direct calls.
Performance tuning after consolidation
Moving from network calls to in-process calls usually improves latency, but a single large monolith can hit memory or CPU bottlenecks under heavy load. Use:
Horizontal scaling of the whole monolith behind a load balancer (since it's stateless per request)
Caching layers for read-heavy modules
Background job queues for slow operations, instead of synchronous in-request work
Selective re-extraction
Not every module belongs in the monolith forever. If, after consolidation and real measurement, one module genuinely needs independent scaling (say, a video processing module that needs GPU instances while the rest of the app doesn't), extract just that one module as its own service. This is the hybrid approach the industry has landed on for 2026: a modular monolith core plus a small number of selectively extracted services for genuine hot paths.
Observability without a full distributed tracing stack
You don't need a service mesh to get visibility. Structured logging with request IDs, combined with basic APM (application performance monitoring) tooling inside the single monolith process, gives most teams enough insight without the overhead of distributed tracing infrastructure.
Real-World Examples
These aren't hypothetical. Several well-known companies have either run modular monoliths at scale or publicly walked back from over-distributed systems.
Shopify runs one of the largest Ruby on Rails monoliths in production, serving millions of merchants. They use a system called Packwerk to enforce module boundaries at the code level, with each "pack" having clear dependencies, explicit public interfaces, and automated boundary checks. They only extract a module into its own service when the data supports it, not by default.
Basecamp, built by 37signals, popularized the term "Majestic Monolith." Their argument is that for a focused team of around 20 engineers, the operational overhead of microservices is pure waste, so they run a single Rails app behind a CDN with background jobs handling async work.
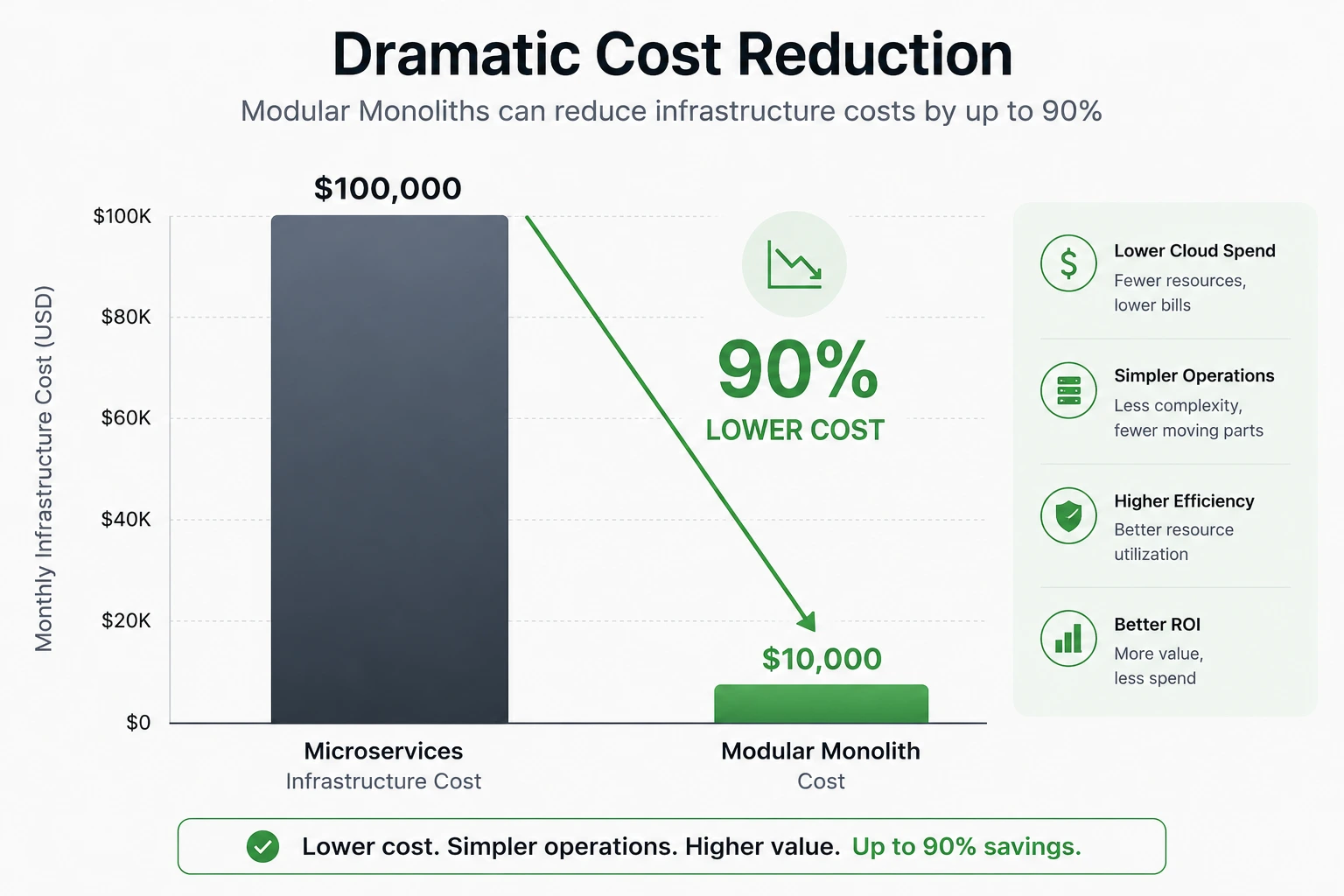
Amazon Prime Video's Video Quality Analysis team is probably the most cited case in this space. They migrated from a distributed microservices setup to a single-process monolith and reported a 90% reduction in infrastructure cost, along with improved scaling capability. It's worth noting, as some 2026 commentary clarifies, that this change applied to a specific audio/video monitoring service rather than "Prime Video becoming a monolith" company-wide — but the underlying lesson holds: a team had split a workload too early, and was paying for it on every single request.
Airbnb and GitHub are both cited as companies that have scaled their core applications as modular monoliths, showing the approach works even for high-traffic platforms, letting teams move fast without the latency tax and operational complexity of microservices.
Even Amazon itself, often credited with popularizing microservices broadly, started as a monolith and only split into services once it had thousands of engineers with genuinely independent teams — reinforcing that the split should follow organizational need, not come first.
A simple anecdote that captures the pattern: a small team builds a payments feature, splits it into a "payment-service," an "invoice-service," and a "notification-service" early on, because that's what the tutorials suggested. Eighteen months later, when a customer reports a failed payment, the on-call engineer has to trace a single request across all three services, two queues, and a shared database — just to find a typo in a retry condition.
That story, almost word for word, has been described by engineering teams reflecting on years spent in microservices architectures they built with enthusiasm and later reconsidered moving back from. One widely shared first-person account from an engineering blog describes exactly this: a team that built a microservices system in 2022 "with so much enthusiasm," only to spend roughly 18 months fighting debugging nightmares before seriously considering a move back to a modular monolith — explicitly noting that copying Netflix's architecture made little sense for a team that wasn't operating at Netflix's scale.
A controlled before-and-after experiment: one engineer ran the exact same mid-sized SaaS application (user management, billing, core product, analytics) under real production load — first as microservices, then merged back into a modular monolith six months later, with peak traffic of 25,000 concurrent users and heavy write operations kept identical across both versions. During the microservices phase, a bug in the notification service triggered a cascading failure that slowed the entire platform during a marketing campaign — the kind of blast-radius problem that strict in-process module boundaries make far less likely.
Segment is another widely cited case: the company moved away from more than 50 services back to a monolith, citing debugging pain and deployment overhead as the deciding factors.
Netflix and Atlassian are useful counterpoints, not blanket endorsements of microservices. Netflix only adopted microservices around 2009, after its monolith genuinely could not sustain its availability and global scaling demands — the split followed proven need.
Netflix's own engineering team has been open about the cost of that choice at scale, reporting that it now runs more than 700 microservices in production, backed by a substantial internal investment in service mesh tooling, custom deployment platforms, full observability stacks, and chaos-engineering practices just to keep that footprint manageable — a level of tooling spend that only makes sense at Netflix's size. Etsy followed a similar arc, starting as a monolith and only introducing service boundaries once team autonomy and feature velocity became real bottlenecks, not before.
Not everyone agrees the "modular monolith" framing is the full answer. Some architects argue that the real failure point isn't monolith-vs-microservices at all, but teams misunderstanding what genuine modularity, ownership, and boundaries mean in the first place — producing what's sometimes called a "distributed monolith": services that are technically separate but still tightly coupled in practice. This is a fair caution: relabeling a tangled codebase as a "modular monolith" without enforcing real boundaries fixes nothing. The discipline matters more than the label.
The Real Cost Numbers (2026 Data)
Beyond the anecdotes, a few independently reported figures help quantify exactly what microservices sprawl costs a typical mid-sized team versus a modular monolith.
Debugging time: a widely cited 2024 DZone analysis found that teams spent roughly 35% more time debugging issues in microservices architectures than in modular monoliths, largely because of distributed request flows that are difficult to reproduce locally.
Infrastructure overhead: research from cloud cost-optimization vendor Cast.ai puts the infrastructure premium for microservices at roughly 30-40% higher than an equivalent monolithic application, driven by per-service overprovisioning, extra networking infrastructure, and duplicated middleware.
Full cost-of-ownership comparison: one detailed 2025-2026 breakdown for a mid-sized application estimated total monthly cost (infrastructure plus platform-engineering headcount) at roughly $1,100-2,300 for a modular monolith versus roughly $4,200-8,500 for an equivalent 10-15 service microservices setup before even counting the extra 1-2 platform engineers (at an estimated $140,000-180,000 each annually) that microservices typically require beyond what a monolith needs.
Team-size threshold: research cited from Thoughtworks suggests organizations with fewer than 50 engineers rarely see a net benefit from microservices, since coordination overhead tends to exceed any independence gained though heavily distributed, multi-timezone teams are something of an exception, since geographic spread can favor the independence microservices provide.
Test reliability: end-to-end test suites tend to become measurably less reliable as services multiply commentary drawing on Google's testing research and State of DevOps data pegs typical end-to-end test reliability at around 70-90% for monoliths versus 40-60% for microservices, with test environments costing low hundreds of dollars a month for a monolith versus thousands to tens of thousands for a microservices setup.
These numbers vary by source and methodology, so treat them as directional rather than exact but they all point the same way: for teams below the scale where microservices are clearly justified, the complexity tax shows up in both engineering time and cloud bills.
Latest Updates (2026)
Software architecture trends 2026 show this isn't a fringe opinion anymore it's backed by industry-wide data and new tooling.
CNCF survey data: a 2025 CNCF survey found that 42% of organizations that had adopted microservices were consolidating services back into larger deployable units, with the primary drivers being economic reality and operational overhead rather than technical limitations.
Service mesh adoption is falling: service mesh adoption dropped from 18% in Q3 2023 to 8% in Q3 2025, signaling that cost not raw scalability has become the main architectural constraint going into 2026.
New "modular monolith" frameworks have matured: tooling such as Spring Modulith for Java/Spring teams and Service Weaver are now widely used to add structure and boundary enforcement to monolithic codebases, alongside Rails' own module conventions and Shopify's open-source Packwerk.
A hybrid architecture has become the recommended default: the 2025-2026 industry consensus recommends a hybrid approach for many teams: a modular monolith core plus two to five extracted services for genuine hot paths starting modular and extracting selectively only when business need justifies it.
AI coding tools are changing the calculus further: as AI coding agents like Claude Code and Cursor read and modify entire codebases, the "cost of change" in tightly coupled, single-codebase systems has shifted, with research data point cited around a 166-to-1 ratio of input tokens to generated tokens making it easier for AI tools to reason about a modular monolith's single codebase than to coordinate changes across dozens of separate service repositories.
"Boring tech" is trending as a deliberate strategy: developers are increasingly choosing simpler tools like SQLite over Kubernetes favoring simplicity over sophistication as architectural decisions shift from "move fast and break things" toward "move deliberately and build sustainably".
Clear thresholds are now part of standard guidance: current recommendations suggest choosing a modular monolith when team size is roughly 10–100 engineers, scale is in the thousands-to-millions of users range, and there are fewer than five dedicated platform engineers while reserving microservices for teams over 100 engineers with genuine independent-scaling needs, polyglot technical requirements, or regulatory isolation mandates such as PCI compliance.
Troubleshooting Checklist
Use this checklist to diagnose whether microservices technical debt is costing you more than it's giving you:
Can you name a real, measured business reason for each separately deployed service?
Do any two services always get deployed together?
Does your team spend more time debugging cross-service issues than building features?
Is your cloud bill rising faster than your user growth?
Do you have fewer than 5 dedicated platform/DevOps engineers supporting 10+ services?
Are on-call engineers regularly tracing a single request across 3+ services to find simple bugs?
Is your team under 100 engineers?
Do most of your services share the same database instance anyway?
Have you measured (not guessed) which workloads actually need independent scaling?
Would your newest engineers describe the system as easy to navigate?
If you checked more "yes" boxes than "no," a modular monolith is very likely the right move for reducing cloud infrastructure costs and distributed systems complexity.
When to Contact Support (or Bring in Outside Help)
Most architecture decisions can be made internally with the framework above, but consider getting outside expertise when:
You're migrating a system processing real money or regulated data (payments, healthcare, finance) and need to validate the consolidation plan against compliance requirements.
Your team has never operated a modular monolith before and wants a second opinion on module boundaries before committing months of work.
You're seeing production incidents during the migration itself and need rapid, experienced triage.
You need to negotiate cloud provider contracts or reserved capacity as part of a cost-reduction plan tied to the architecture change.
Your current vendor (cloud platform, observability tool, service mesh provider) needs to be involved in a deprecation or downgrade plan as you consolidate services.
In these cases, bring in a senior architect, your cloud provider's solutions team, or a specialized consultancy with documented modular monolith migration experience rather than treating this as a purely internal engineering decision.
FAQ Section
A modular monolith is one deployable application with strictly enforced internal module boundaries, while microservices split the application into many independently deployable services that talk to each other over a network. The modular monolith keeps communication in-process; microservices use network calls.
No. A traditional monolith often has blurry, undisciplined boundaries between parts of the code. A modular monolith deliberately enforces strict module boundaries, often with tooling, so it gets many of the organizational clarity benefits of microservices without the network overhead.
Look at team size, real traffic per service, and operational burden. If your team is under roughly 50–100 engineers, most of your services are deployed together, and you're spending more time on operational overhead than feature work, consolidation is usually justified.
Not for most teams. A modular monolith can scale horizontally as a whole, which covers the needs of the vast majority of applications. Only when a specific workload genuinely needs independent scaling — verified by real data — should you extract that one piece as its own service.
It's the hidden cost that builds up in a microservices system over time: duplicated logic across services, services that secretly depend on each other's deployment timing, complicated workarounds for data consistency, and growing operational tooling that nobody fully maintains.
Usually one shared database instance, but with each module owning its own tables and schema. Modules don't query each other's tables directly — they go through each module's defined interface, preserving the same kind of separation microservices gives you, without separate database instances.
Yes, using a reverse Strangler pattern: build the new module, redirect traffic to it gradually, monitor closely, and only retire the old service once the new module is fully proven in production.
Shopify, Basecamp, Airbnb, and GitHub are commonly cited examples of companies running large, high-traffic applications as modular monoliths rather than fully distributed microservices.
No. Microservices are still the right choice for organizations with 100+ engineers, genuine independent scaling needs, polyglot technology requirements, or regulatory isolation mandates. What's changing is the default assumption — teams no longer reach for microservices automatically.
AI coding agents tend to work more efficiently across a single, well-organized codebase than across dozens of separate service repositories, since they can read and reason about the whole system at once. This is becoming an additional factor favoring modular monoliths for teams that rely heavily on AI-assisted development.
Conclusion
The modular monolith vs microservices decision in 2026 isn't about picking a side in an old argument, it's about matching your architecture to your actual team size, traffic, and operating model. The data backs this up: a significant share of organizations that adopted microservices are now consolidating, not because microservices are bad technology, but because most teams paid for complexity they never needed.
If you're dealing with rising cloud infrastructure costs, growing distributed systems complexity, or a backlog of microservices technical debt, the path forward doesn't have to be a risky rewrite. Map your real traffic, identify your true module boundaries, enforce them with tooling, and migrate gradually. Keep the door open to extract a service later — but only when the evidence, not the trend, tells you to.
Start small: pick one pair of "fake" microservices in your system this week, and sketch out what consolidating them would look like. That single step is often enough to show your team whether a modular monolith is the right next move.