Quick Answer
Memory efficient programming is back in 2026 because DRAM and HBM prices have roughly doubled amid a global memory shortage, AI inference now eats most cloud budgets, and edge/on-device AI demands small footprints. Developers who write leaner code save real money on cloud bills, fit more on constrained hardware, and reduce latency — making memory optimization a competitive skill again, not a forgotten one.
TL;DR
DRAM and NAND prices surged over 100% in 2025–2026 because AI data centers are consuming roughly 70% of global memory chip output.
Cloud providers are passing memory shortage costs onto customers, with memory-heavy services like databases and caches seeing the steepest price hikes.
Inference, not training, now dominates AI infrastructure budgets (about 80% of spend), and GPU memory (VRAM/HBM) is the single biggest cost lever.
Quantization (running models in 4-bit or 8-bit instead of 16-bit) cuts memory needs by up to 4x with minimal quality loss — a direct application of memory-efficient thinking.
Rust's adoption has plateaued somewhat as a "rewrite everything" language, but its core value — efficient memory without a garbage collector — keeps growing in kernels, embedded systems, and AI runtimes.
Memory efficiency isn't just about C and Rust anymore; it shows up in Python data pipelines, JavaScript bundles, database schemas, and LLM serving stacks.
The skills that matter in 2026: profiling before optimizing, understanding allocation patterns, choosing the right data structures, and knowing when NOT to over-optimize.
This is a return to fundamentals driven by economics (memory costs money) rather than nostalgia for the embedded-systems era.
Enterprise virtualization costs have jumped even harder than retail cloud pricing — HBM/DRAM prices are up roughly 170% in the past year, and HPE estimates 20–40% of enterprise infrastructure sits overprovisioned and unused.
Smartphone makers are reversing a decade of progress: 4GB RAM base models and microSD slots are coming back in 2026 because DRAM has gotten too expensive to keep adding to budget devices.
Not everyone agrees this will change how most developers actually code day to day — a large, vocal part of the developer community expects bloat to just get passed on to customers as higher prices instead of getting fixed.
Rewriting a service in a faster language only pays off if you do the math first. A Python-to-Rust rewrite that saves real money on compute can still take years to break even against the engineering cost of the rewrite itself.
Introduction
In early 2026, DRAM contract prices jumped from around $7 to roughly $19.50 per unit in a matter of months. Some DDR5 modules spiked more than 100% quarter over quarter, and SSD/NAND pricing climbed 55–60% on top of that. This wasn't a normal commodity cycle. AI data centers are now consuming an estimated 70% of all memory chips produced globally, and manufacturers like SK Hynix and Micron have their entire 2026 HBM (High Bandwidth Memory) production already sold out to hyperscalers.
If you write software for a living, this matters more than it sounds. For the better part of a decade, memory was treated as basically free. RAM was cheap, cloud instances came with generous defaults, and "just add more memory" was a legitimate engineering strategy. That era is ending. Cloud providers are already passing some of this cost increase through to customers, and memory-heavy services databases, caches, anything with a high DRAM ratio are seeing the steepest price hikes of any cloud line item.
At the same time, AI inference has become the dominant cost center for any company shipping AI features. Serving models, not training them, now eats roughly 80% of AI infrastructure budgets, and the single biggest lever for inference cost is how much GPU memory your workload actually needs: KV cache size, batch size, quantization level, and model footprint all map directly to dollars per request.
This article explains exactly why memory-efficient programming has come back into focus in 2026, what's actually changed in the hardware and economics, and how to apply memory-efficient thinking whether you're writing systems code in Rust and C, building data pipelines in Python, or serving LLMs in production. You'll get real benchmarks, code examples, a practical optimization workflow, and answers to the questions developers are actually asking right now.

Why Memory Efficiency Disappeared (And Why It's Back)
The "memory is cheap" decade
Through most of the 2010s and early 2020s, RAM prices fell steadily, cloud autoscaling made it trivial to throw more memory at a problem, and higher-level languages with garbage collection became the default for almost everything outside of kernels and embedded firmware. Optimizing memory usage by hand stopped being a daily skill for most application developers. It became something you only thought about if you worked in games, embedded systems, or high-frequency trading.
What broke that assumption
Three things converged in 2025–2026:
A genuine memory supply shock. HBM, the memory type used in every AI accelerator, consumes three to four times the wafer capacity of standard DDR5 to manufacture. Since HBM generates three to five times more revenue per wafer than consumer memory, manufacturers reallocated fab capacity toward HBM and let the consumer/server DRAM market compete for whatever capacity remained. The result: DRAM contract prices have roughly doubled, and that gap won't close until new fabs come online in late 2027 or 2028.
Inference economics, not training economics, now drive AI cost. A model serving 10,000 requests a day at 500ms latency typically crosses over from training-dominated to inference-dominated cost within three to six months of launch. Once you're in that regime, the size of your KV cache and your model's memory footprint directly determine your bill.
Edge and on-device AI went mainstream. Phones, laptops, and even Raspberry Pi-class devices are now expected to run real models locally. A 4-bit quantized model needing 4GB of RAM instead of 16GB isn't a nice-to-have anymore — it's the difference between a feature that ships and one that doesn't.
None of this is nostalgia. It's economics. When memory itself becomes the scarce, expensive resource — whether that's DRAM in a data center or VRAM on a GPU — the code that uses less of it wins.
What "Memory-Efficient Programming" Actually Means in 2026
Memory efficiency isn't one technique. It shows up differently depending on where you sit in the stack:
Layer | What memory efficiency looks like | Why it matters now |
|---|---|---|
Systems / kernel code | Manual allocation control, stack vs. heap decisions, zero-copy operations | Rust's official mainline support landed in the Linux kernel, making safe, efficient low-level code more accessible |
Application code (Python, JS, Java, Go) | Choosing the right data structures, avoiding unnecessary object copies, streaming instead of loading everything into memory | Cloud memory-tier pricing is rising, and inefficient code now shows up directly on the bill |
AI / LLM serving | Quantization (FP8, INT8, INT4), KV cache management, batching strategy | GPU memory (VRAM/HBM) is the single most expensive and most constrained resource in AI infrastructure |
Embedded / edge | Static memory allocation, avoiding fragmentation, fitting models or firmware into kilobytes | On-device AI and IoT both demand small, predictable footprints |
Database / infrastructure | Index design, caching layers, connection pooling, query memory usage | DRAM-heavy services like databases and caches are seeing the steepest cloud price increases |
The common thread across every layer: understand how much memory your code actually needs, and don't pay for more than that.
The Hard Numbers: Why This Isn't Just a Vibe Shift
It's worth being specific about the data, because "memory matters again" is the kind of claim that's easy to wave at without evidence.
DRAM and HBM supply is the real constraint. TrendForce's Q1 2026 projections put PC DRAM up 105–110% quarter over quarter and server DRAM up 88–93%. Micron's leadership has acknowledged the company can only meet 50–66% of demand from its core customers.
GPU memory drives inference cost directly. For a 70B-parameter model like Llama 2 at FP16 with a 4K context window, the KV cache alone runs about 0.4GB per concurrent request. At 200 concurrent requests, that's 80GB of cache before you've done anything else — which is why a GPU with more VRAM (like the H200's 141GB) can beat a cheaper, lower-memory GPU (the H100) once concurrency climbs high enough.
Quantization is the single highest-leverage memory optimization in AI right now. Cutting KV cache precision from FP16 to INT8 or FP8 reduces VRAM usage by 30–50% for long-context workloads, freeing capacity for more concurrent requests without buying more hardware.
Right-sizing matters as much as code-level optimization. An A100 80GB instance costs the same whether you use 20GB or 80GB of it — so a workload that fits in 24GB but runs on an 80GB card is paying roughly 3.3x for memory it never touches.
This is the practical case for memory-efficient programming in one sentence: every gigabyte you don't need is a gigabyte someone is still billing you for.
It's Not Just Servers: Phones and Enterprise IT Are Feeling It Too
The memory squeeze isn't confined to data centers. It's reshaping consumer hardware and enterprise IT budgets at the same time.
Smartphones are going backward. Industry analysis from TrendForce points to memory prices rising sharply again through 2026, putting real pressure on smartphone and notebook makers. The practical result: entry-level Android phones are expected to ship with 4GB of RAM again — a spec last common around 2018 — while mid-range phones that currently offer 12GB are projected to max out closer to 8GB, and microSD slots are returning as a cheaper alternative to soldered storage. One DRAM chip that cost roughly $6.84 in late 2025 was pricing closer to $27 a few months later. If you're building mobile apps or on-device AI features, this is a hard constraint, not a hypothetical one — the device your app needs to run well on in 2026 may have less memory than the device it ran on in 2022.
Enterprise virtualization costs have jumped even harder than retail cloud pricing. One industry analysis puts the year-over-year increase in HBM and DRAM costs at roughly 170%, with some virtualization licensing models more than doubling in price on top of that. The response from infrastructure vendors has been telling: rather than simply recommending "buy more memory," the emerging playbook is workload-level optimization — getting real visibility into what's actually using memory, then applying techniques like memory ballooning (dynamically reassigning unused memory across virtual machines on the same host) to safely oversubscribe physical RAM.
Enterprise estimates suggest 20–40% of infrastructure today is overprovisioned, sitting idle while still being paid for in full. That's not a code-level memory leak — it's an organizational visibility problem, and it's the same root cause behind the bloated cloud bills described earlier in this article, just at enterprise scale.
The pattern across consumer hardware, enterprise IT, and AI infrastructure is the same: when memory supply tightens, the cost of not knowing exactly how much memory your software actually needs goes up sharply.
Language and Tooling Trends: Where Memory Efficiency Is Actually Happening
Rust: mature, not hyped
Rust's trajectory in 2026 is more nuanced than the "Rust is taking over everything" narrative from a few years ago. TIOBE data shows Rust's ranking has actually slipped slightly after peaking, suggesting broad enterprise adoption is plateauing — the language remains genuinely difficult to learn for non-specialists, and mandating full rewrites of working C/C++ codebases has proven harder to justify than expected for ordinary business software.
But the places where Rust's memory model is winning are exactly the places where memory efficiency matters most: official mainline support for Rust landed in the Linux kernel, Android's codebase has steadily incorporated it, and embedded/automotive teams cite measurable wins — including reports of significantly fewer memory-related bugs compared to equivalent C implementations, with deterministic, garbage-collector-free memory handling that keeps latency predictable in real-time systems.
Practical takeaway: Rust isn't winning because it's trendy. It's winning in the specific domains — kernels, embedded systems, real-time control — where memory efficiency is non-negotiable and the learning curve is worth paying for.
C and C++: still the default where it counts
C++26 has closed some of the safety gap with new compile-time checks, and reports suggest these features have meaningfully reduced segmentation faults in large production environments with minimal performance overhead. For latency-critical domains like high-frequency trading, C++'s direct memory control still gives it an edge over Rust's runtime safety checks. The realistic 2026 takeaway is that C/C++ and Rust now trade wins depending on workload — pure micro-benchmarks often favor C++ by a small margin, while real-world systems with concurrency and safety requirements often favor Rust.
Beyond systems languages: memory efficiency in everyday code
You don't need to write Rust to benefit from memory-efficient thinking. The same principles apply in:
Python data pipelines: using generators and chunked processing instead of loading entire datasets into memory.
JavaScript/TypeScript: trimming bundle size and avoiding memory leaks from uncleared event listeners or closures in long-running Node services.
Java/Go backend services: tuning garbage collector behavior and object pooling instead of just scaling up heap size.
LLM application code: managing context window size and avoiding unnecessary duplication of large prompts or embeddings in memory.
Practical Optimization Techniques (With Code)
1. Profile before you optimize
The single most common mistake in memory optimization is guessing. Use real tools:
bash
# Rust: visualize where time and allocations go cargo install flamegraph cargo flamegraph --bin your_binary # Track memory allocation hotspots specifically heaptrack ./your_binary
python
# Python: measure actual memory usage of objects and functions
import tracemalloc
tracemalloc.start()
# ... run the code you're investigating ...
current, peak = tracemalloc.get_traced_memory()
print(f"Current memory usage: {current / 1024:.1f} KB; Peak: {peak / 1024:.1f} KB")
tracemalloc.stop()
Expected output for the Python snippet: two numbers showing current and peak memory in kilobytes. If peak is dramatically higher than current, you likely have a short-lived spike (e.g., loading a whole file before processing it) worth fixing.
Common mistake: optimizing the function that "feels" slow instead of the one the profiler flags. Intuition about memory usage is often wrong, especially in languages with garbage collection.
2. Stream instead of loading everything
python
# Memory-inefficient: loads the entire file into RAM
with open("large_dataset.csv") as f:
lines = f.readlines()
for line in lines:
process(line)
# Memory-efficient: processes one line at a time
with open("large_dataset.csv") as f:
for line in f:
process(line)
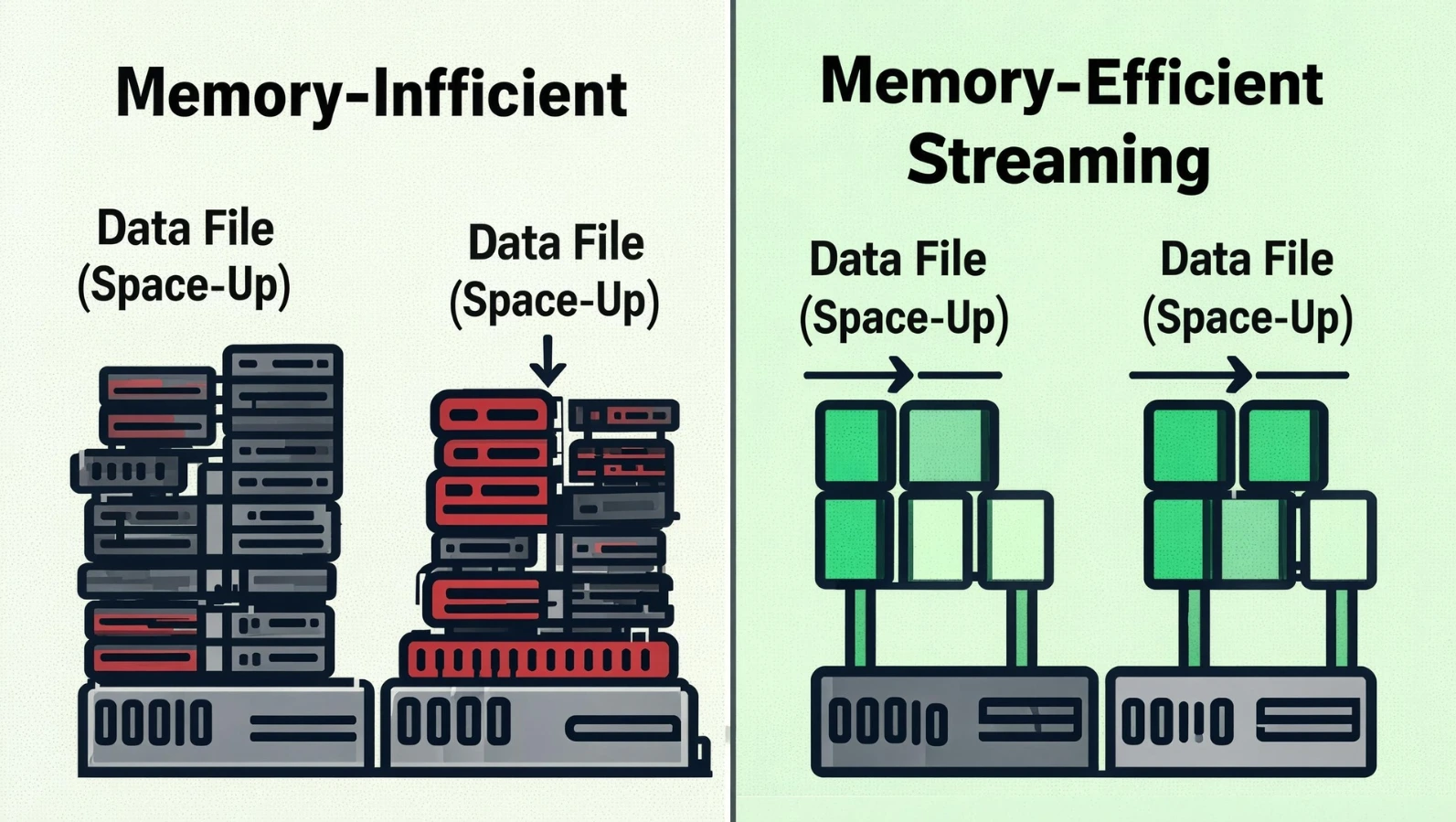
The second version keeps memory usage flat regardless of file size. The first version's memory usage scales linearly with file size — fine for a 10MB file, a real problem for a 10GB one.
3. Choose data structures deliberately
python
# Memory-heavy: a list of dicts for tabular data
records = [{"id": i, "value": i * 2} for i in range(1_000_000)]
# Memory-light: parallel arrays (or a typed library like NumPy/Polars)
import numpy as np
ids = np.arange(1_000_000)
values = ids * 2
A list of a million Python dictionaries carries significant per-object overhead. NumPy arrays store the same data in contiguous, fixed-size memory blocks — often using a fraction of the RAM for the same logical data.
4. Reduce allocations in hot paths (Rust example)
rust
// Allocates a new String on every call - wasteful in a loop
fn greet(name: &str) -> String {
format!("Hello, {}", name)
}
// Reuses a buffer instead of allocating repeatedly
fn greet_into(name: &str, buf: &mut String) {
buf.clear();
buf.push_str("Hello, ");
buf.push_str(name);
}
In a loop calling this thousands of times per second, the second version avoids repeated heap allocation and deallocation, which reduces both memory churn and CPU time spent on the allocator.
5. Quantize AI workloads instead of just buying bigger GPUs
If you're serving LLMs, the highest-leverage "memory optimization" most teams can make is reducing numeric precision rather than rewriting application code:
- FP16 → FP8/INT8 for KV cache: roughly 30–50% VRAM reduction for long-context workloads.
- FP16 → INT4 for model weights: up to 4x reduction in memory footprint, with quality tradeoffs that need testing per use case.
Common mistake: quantizing the whole model without testing quality on your specific task. Quantization affects different tasks differently — always benchmark accuracy before shipping, not just memory savings.
The Honest Counter-Argument: Will Most Developers Actually Change?
It's worth being honest about the skepticism here, because a "comeback" narrative is easy to overstate.
A widely discussed Hacker News thread asked directly whether the memory shortage would push programmers toward more efficient code, and the answers were split in a useful way. Several engineers at large tech companies reported concrete, current responses — one described a major goal for the coming year specifically focused on reducing server RAM requirements in direct response to rising costs. But the more common prediction was more cynical: most teams will keep shipping memory-heavy software, and the cost will simply get passed on to customers as higher subscription prices rather than solved through engineering effort.
Several commenters pointed out that the real driver isn't algorithms or data structures — it's bloated runtime choices like bundling an entire Chromium browser to ship a chat app, a pattern Electron-based desktop apps are frequently criticized for.
There's also a structural reason change is slow: developers themselves often work on machines with far more memory than the average end user, which removes the personal, day-to-day pressure that would otherwise nudge coding habits. And because cloud and SaaS costs are largely invisible to end users, businesses have historically found it easier to raise prices than to fund a multi-week optimization project.
The realistic takeaway: expect uneven adoption. Domains where memory cost hits the P&L directly, AI infrastructure, cloud-native backend services, embedded and mobile will optimize aggressively because the savings are measurable and large. General-purpose web and desktop software, where the cost of inefficiency is diffused across millions of end users' RAM rather than concentrated on a company's bill, will likely change more slowly, if at all.
Do the Math Before You Rewrite
One of the most common mistakes in 2026's renewed enthusiasm for efficient code is skipping the cost-benefit analysis before committing to a rewrite.
A useful framing from the sustainable-software community: if a Python service costs $47,000 a year to run and the same workload in Rust would cost roughly $8,200 a year, that's a real $38,800 annual savings. But if the rewrite takes four engineers six months, the fully loaded cost of that effort can run into the hundreds of thousands of dollars pushing the break-even point to nearly a decade. Most services don't live that long without being deprecated, redesigned, or replaced first.
This doesn't mean efficient work isn't worth it, it means the decision should be made with real numbers, not benchmark enthusiasm. The same analysis is worth applying to memory specifically: estimate your actual current memory cost (instance pricing, GPU memory tier, or DRAM-heavy database tier), estimate the realistic savings from a targeted optimization or a language change, and weigh that against engineering time before committing to a rewrite. Often the better ROI is a narrower fix — replacing one hot-path data structure, switching one memory-hungry dependency, or right-sizing one oversized instance — rather than a full-language migration.
Best Practices for Memory-Efficient Code
Measure before you optimize. Profilers exist because human intuition about memory usage is unreliable, especially across language runtimes with hidden overhead.
Prefer streaming and chunking over "load it all" patterns. This keeps memory usage proportional to what you're actively processing, not your total dataset size.
Match your data structure to your access pattern. Hash maps, arrays, and trees all have different memory and performance tradeoffs — pick based on how you'll actually read and write the data, not habit.
Right-size infrastructure to actual usage, not worst-case assumptions. Paying for an 80GB GPU instance when your workload needs 24GB is a recurring cost, not a one-time mistake.
Quantize AI workloads deliberately and test quality. Memory savings from quantization are real, but only valuable if output quality holds up for your specific use case.
Reuse buffers and pools in hot paths. Allocation and deallocation aren't free, even in garbage-collected languages — repeated allocation in tight loops is one of the most common hidden costs.
Don't over-optimize cold paths. Memory efficiency effort should go where memory pressure actually exists — a settings page that runs once per session doesn't need the same scrutiny as a request-handling hot loop.
Common Mistakes (And Why They Happen)
Optimizing without profiling first. This happens because profiling feels like overhead when you're confident you already know the bottleneck. It's almost always wrong; profile first.
Treating cloud memory as infinite because it's "just a config change." This habit formed during the cheap-RAM decade and hasn't caught up with 2026 pricing realities, where memory-heavy cloud services are seeing some of the steepest cost increases.
Rewriting working code in Rust or C "for performance" without measuring the actual bottleneck. This happens because of hype rather than data — and given Rust's real learning curve, the investment only pays off when memory safety or efficiency is genuinely the constraint.
Quantizing AI models without re-testing accuracy. Teams chase memory savings and skip the evaluation step, then discover quality regressions after deployment.
Ignoring GPU right-sizing. Many teams default to the biggest available GPU instance out of caution, then pay 2–3x more than necessary for memory capacity they never use.
Advanced Tips
Track cost-per-request or cost-per-million-tokens as a real engineering metric, not just an finance afterthought — GPU hours alone don't tell you if cost is rising due to traffic growth or efficiency regression; pairing GPU hours with token counts gives you a real efficiency signal.
Set budget alerts at 80%, not 100%, for memory-heavy infrastructure — by the time you hit your limit, there's no time left to course-correct.
For LLM serving, calculate KV cache size explicitly using the formula: KV per request ≈ 2 × num_layers × num_kv_heads × head_dim × seq_len × bytes_per_element. This turns "memory optimization" from guesswork into a number you can act on.

Consider on-device or hybrid inference for high-frequency, latency-sensitive tasks. Apple Silicon's unified memory architecture draws from a different supply pool than standard server DRAM, which can partially insulate local-inference workloads from data center memory shortages.
In virtualized enterprise environments, look into memory ballooning before buying more hardware. This technique dynamically reassigns unused memory across virtual machines on the same physical host, since not all VMs consume their full allocation at the same time — it's one of the highest-leverage ways to recover capacity that's already paid for but sitting idle.
Run a break-even calculation before any language rewrite. Compare the realistic annual savings against the fully loaded cost of the engineering time required, including the maintenance burden of a second language in your stack — a rewrite that takes years to pay off is rarely worth it for a service likely to change shape before then.
Revisit reserved vs. on-demand infrastructure commitments quarterly. Memory and GPU pricing is moving fast enough in 2026 that a setup that was optimal three months ago can be meaningfully more expensive today.
Community Insights
Developer discussions across Hacker News and Reddit in 2026 reflect a genuinely mixed picture rather than a simple "memory efficiency is back" consensus:
Praise for Rust's kernel-level wins is widespread among systems engineers, especially after Rust's official mainline support in the Linux kernel — seen as validation that memory-safe, efficient code can coexist with decades-old C codebases.
Frustration with "rewrite everything in Rust" mandates shows up frequently, with engineers pointing out that the learning curve makes sense for kernel developers and embedded teams, but borders on overkill for an internal HR dashboard or a standard REST API.
AI infrastructure threads are dominated by cost anxiety. Discussions about GPU memory shortages, HBM allocation, and rising DRAM prices show developers treating memory capacity as a planning constraint for the first time in years, not just a config setting.
A recurring theme: efficiency gains get absorbed by new demand. Several community discussions note that cheaper inference doesn't reduce total spend — it unlocks more usage, echoing the classic economic pattern where lower per-unit cost increases total consumption rather than total savings.
A direct Hacker News debate split the room. Asked point-blank whether the memory shortage would push programmers toward more efficient code, some engineers described concrete internal projects already underway to cut server RAM usage, while many others predicted businesses will simply raise prices rather than fund optimization work — with Electron-style bundled-browser apps repeatedly singled out as the most visible, least-defended source of bloat.
Independent benchmarking pushes back on "Rust always wins." A widely shared comparison of eight languages on real automation workloads (data cleaning, transformation, export) found Go's balance of simplicity and concurrency made it the most effective choice overall for that workload, even though Rust edged it out narrowly on raw line-processing speed — a reminder that "memory efficient" and "fastest for my specific workload" aren't always the same question.
Energy-efficiency research adds a wrinkle most cost discussions skip. A frequently cited benchmark shows C is roughly 75x more energy-efficient than Python for pure computation, but Python's memory usage is only about 2.8x C's — meaning Python's overhead is concentrated in CPU cycles (type checking, dictionary lookups, reference counting), not memory footprint. That distinction matters when deciding whether a "performance problem" is actually a memory problem at all.
Latest Updates (2026)
A few concrete, dated developments worth tracking:
Linux kernel support for Rust reached a major milestone, with mainline kernel releases finalizing official Rust support alongside other systems-level updates — a signal that memory-safe, efficient code is now a first-class citizen in the most performance-critical open-source project in existence.
HBM production for 2026 is fully allocated at major manufacturers including SK Hynix, with Micron's leadership confirming it can meet only 50–66% of demand from core customers — meaning the memory shortage affecting both AI infrastructure and consumer hardware will persist through the rest of the year.
Consumer GPU upgrade cycles have stalled, with next-generation consumer cards from major vendors pushed out, partly due to manufacturers prioritizing AI-accelerator memory production over consumer-grade silicon.
If you're reading this after mid-2026, treat the specific pricing figures above as historical reference points — verify current DRAM, HBM, and GPU cloud pricing directly, since this market is moving quickly.
Future Outlook
The memory shortage driving renewed interest in efficient code isn't expected to resolve quickly. New fab capacity for memory chips typically takes years to come online, and current projections put meaningful supply relief at late 2027 or 2028 at the earliest. That means the economic pressure favoring memory-efficient code — in both traditional software and AI systems — is likely to persist for at least the next 18–24 months.
At the same time, custom AI silicon (TPUs, Trainium, and similar in-house chips) is projected to take a growing share of the AI accelerator market, partly as a direct response to GPU memory costs and availability. This will likely push more AI workloads toward architecture-specific memory optimization rather than one-size-fits-all GPU code.
The long-term pattern worth watching: efficiency gains tend to get absorbed by new demand rather than shrinking total spend. Cheaper, more memory-efficient inference doesn't reduce AI infrastructure budgets — it tends to enable more usage, which is exactly what happened as agentic workflows scaled from cheap prototypes to expensive production systems in 2025–2026.
Memory-efficient programming, in other words, isn't a one-time fix. It's becoming a permanent, ongoing discipline — the same way cost-conscious cloud architecture became permanent after the early cloud-cost surprises of the 2010s.
FAQ
No. The principles apply everywhere — Python data pipelines, JavaScript backends, database design, and AI serving infrastructure all benefit from memory-conscious decisions, even though the specific techniques differ by layer.
AI data centers are consuming an estimated 70% of global memory chip production, and manufacturers have reallocated fab capacity toward higher-revenue HBM (used in AI accelerators) at the expense of standard DRAM supply, pushing prices up sharply.
Usually not, unless you're working on kernels, embedded systems, real-time control, or another domain where memory safety and efficiency are genuinely the bottleneck. For most application-level software, targeted optimization in your existing language delivers better ROI than a full rewrite.
Quantization. Moving from FP16 to FP8/INT8 for KV cache, or to INT4 for model weights, delivers the largest memory reductions — often 30–50% for cache and up to 4x for weights — though quality should always be re-tested after quantizing.
Profile it. Tools like tracemalloc (Python), heaptrack and cargo-flamegraph (Rust), or your language's equivalent will show you actual allocation patterns rather than relying on guesswork.
Broad enterprise adoption growth has plateaued somewhat according to TIOBE rankings, largely due to Rust's learning curve. However, adoption in performance-critical domains like kernels and embedded systems continues to deepen, including official mainline support in the Linux kernel.
Yes, concretely. Running a workload that needs 24GB on an 80GB GPU instance means paying for roughly 3.3x more memory capacity than necessary — and memory-heavy cloud services are facing some of the steepest price increases of any infrastructure category in 2026.
KV cache stores intermediate attention data for each token during LLM inference. Its size scales with context length and concurrent requests — for a 70B model at FP16 with a 4K context, it can reach roughly 0.4GB per request, which adds up fast at scale and is a primary driver of GPU memory requirements.
For latency-sensitive, privacy-constrained, or high-frequency tasks, yes — quantized models and dedicated NPUs in modern phones and laptops can now run meaningful AI workloads locally, partially insulating teams from cloud memory cost increases.
Unlikely in the near term. Current fab capacity for advanced memory is fully allocated through 2026, and new capacity generally takes until late 2027 or 2028 to come online, so elevated prices are expected to persist for the next year or two.
It depends on access patterns, but a common win is replacing collections of small objects (like lists of dictionaries) with columnar or array-based structures (like NumPy arrays or Polars DataFrames) when working with large, uniform datasets.
Both, and they interact. Right-sizing hardware (GPU memory tier, instance type) addresses the infrastructure side; profiling and optimizing allocation patterns, data structures, and quantization addresses the code side. Neither alone solves a memory cost problem completely.
DRAM costs have risen sharply enough that smartphone makers are cutting specifications to protect margins — entry-level phones are expected to return to 4GB RAM configurations, a spec last common around 2018, with mid-range devices also seeing reduced memory tiers.
Mostly visibility. Estimates suggest 20–40% of enterprise infrastructure is overprovisioned and sitting idle, largely because teams lack real-time insight into actual usage across hybrid and multi-cloud environments — not because every application itself is badly written.
Sometimes, but always run the math first. Compare the realistic annual infrastructure savings against the fully loaded engineering cost of the rewrite — a project that takes years to break even is rarely worth it if the service is likely to be redesigned or deprecated before then.
Garbage-collected languages handle deallocation automatically, which reduces certain classes of bugs but doesn't eliminate memory overhead — frequent allocation in hot loops still creates real performance and memory churn costs, even with a GC managing cleanup.
Conclusion
Memory-efficient programming isn't returning because of nostalgia for the embedded-systems era — it's returning because memory itself became expensive and scarce again. DRAM and HBM prices have roughly doubled in the past year, AI inference now dominates infrastructure budgets, and GPU memory capacity directly determines what you pay per request. Whether you're maintaining a kernel in Rust, building a Python data pipeline, or serving an LLM in production, the same underlying discipline applies:
measure what your code actually uses, choose data structures and infrastructure that match your real requirements, and treat every unnecessary gigabyte as a recurring cost rather than a rounding error.
The teams that adapt fastest to this shift won't be the ones rewriting everything in a systems language overnight. They'll be the ones who profile before optimizing, right-size their infrastructure, quantize their AI workloads deliberately, and build memory-efficient programming back into their everyday engineering habits — because in 2026, that's no longer optional.