Introduction
For the first time in this AI cycle, an open-weight model is getting compared seriously to Claude not as a curiosity, but as a real contender. GLM 5.2, released by China's Zhipu AI (operating internationally as Z.ai) on June 13, 2026, has triggered a wave of headlines claiming it "beats Claude" on coding benchmarks. Some of that buzz is real. A lot of it is marketing math wearing a lab coat.
This piece looks at what GLM 5.2 actually is, what Claude (specifically Claude Opus 4.8 and Claude Code) actually does, and what the benchmark numbers say once you strip out the spin. If you're trying to decide which model to build with or you're just tired of conflicting "X beats Y" posts this is the breakdown you came for.
Why GLM 5.2 is creating buzz
Three things collided at once. First, GLM 5.2 shipped with a fully usable 1-million-token context window, two selectable reasoning modes (High and Max), and a permissive MIT license, a combination almost no other open model offers in one package. Second, the model launched just 48 hours after a US export-control directive forced Anthropic to suspend foreign access to its newest top-tier models, Claude Fable 5 and Claude Mythos 5, giving Zhipu's "fully open, no regional restrictions" pitch unusually good timing.
Third, Zhipu's Hong Kong-listed stock jumped more than 30% in a single trading day on the news, which pulled financial journalists into a story that started as a developer-tools release.
Independent community reaction has also been louder than typical open-model launches. Several practitioners on social media described GLM 5.2 as the first open-weight model that feels "frontier-adjacent" in daily coding use, while still noting real gaps most prominently, the model ships without vision/multimodal support.
What makes Claude the current coding leader
Claude's reputation in coding circles wasn't built on a single launch. Claude Code Anthropic's command-line agentic coding tool has become a default for many professional developers doing multi-file refactors, codebase migrations, and long agentic sessions. Anthropic's current generally-available flagship, Claude Opus 4.8 (released May 28, 2026), scores 88.6% on SWE-bench Verified and 69.2% on the considerably harder SWE-bench Pro, both of which sit ahead of GPT-5.5 and Gemini 3.1 Pro on the same tasks according to Anthropic's own system card.
Opus 4.8 also introduced "dynamic workflows," letting Claude Code dispatch hundreds of parallel subagents on a single hard problem.
Note: Claude's newest tier, Fable 5, briefly posted a self-reported 95% on SWE-bench Verified before being pulled from foreign access due to the export-control order. Because that model isn't broadly available right now, this article treats Opus 4.8 as the practical, accessible Claude baseline for comparison, with notes on Fable 5 where relevant.
Why everyone is comparing them
Open-weight models rarely get directly benchmarked against the most expensive closed frontier models, because the gap has historically been too wide to make for an interesting headline. GLM 5.2 changes that math: it's roughly one-sixth the API cost of Opus 4.8, it's self-hostable, and on several agentic and coding benchmarks it lands close enough to invite a real comparison rather than a dismissal.
Quick answer
No, GLM 5.2 does not beat Claude Opus 4.8 across the board on coding benchmarks. It comes close on some agentic and terminal-style tasks, it is dramatically cheaper, and it's the strongest open-weight coding model currently available but on the benchmarks that matter most for production software engineering (SWE-bench Verified and SWE-bench Pro), Claude Opus 4.8 still leads by a meaningful margin. Where GLM 5.2 genuinely wins is price-to-performance and openness, not raw coding accuracy.
What is GLM 5.2?
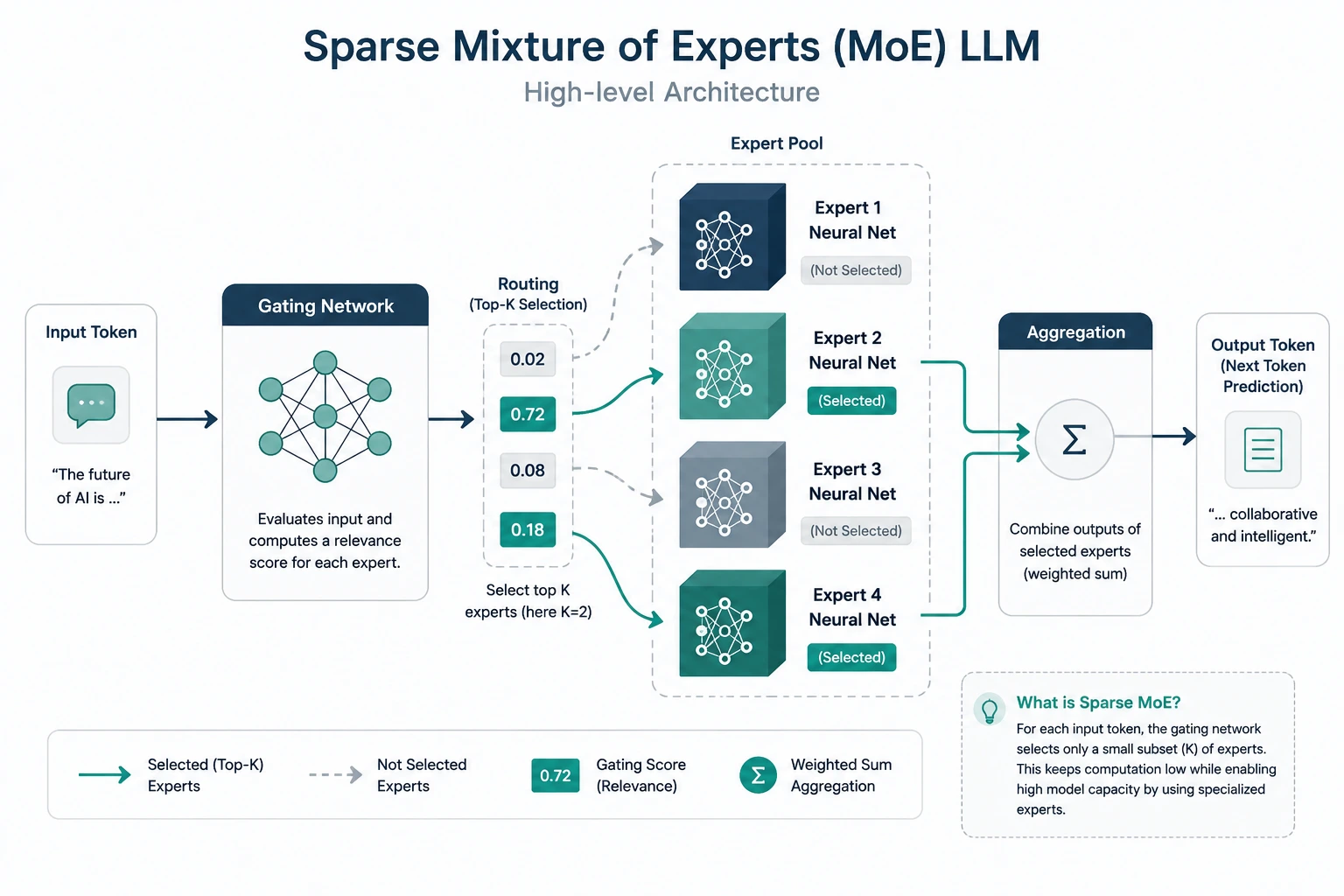
Developer: Zhipu AI, a Beijing-based foundation model lab founded in 2019, operating its global-facing brand as Z.ai. Zhipu went public on the Hong Kong Stock Exchange in January 2026.
Release: GLM 5.2 launched on June 13, 2026, first through Zhipu's GLM Coding Plan, with open weights and a standalone API rolling out across providers in the days that followed. It succeeds GLM 5.1 in the GLM-5 model family.
Architecture: GLM 5.2 is a sparse Mixture-of-Experts (MoE) model with roughly 744 billion total parameters and about 40 billion active parameters per token the same overall scale as GLM 5.1, but with a context window quadrupled to 1 million tokens. The headline architectural addition is "IndexShare," a sparse-attention technique that reuses top-k attention indices across groups of layers to keep long-context inference costs manageable.
Model sizes: A single primary 744B/40B-active configuration, distributed both as a hosted API model and as open weights (published on Hugging Face and ModelScope) for self-hosting.
Capabilities: Two selectable reasoning-effort modes High, for everyday use, and Max, for complex multi-step coding and planning tasks where the model needs to revise its approach across a long sequence.
Context window: 1,000,000 input tokens, with a 131,072-token output limit among the largest practically usable context windows of any openly available model.
Reasoning: GLM 5.2 is explicitly tuned for multi-step reasoning, logical consistency, and instruction following, particularly in mathematical and workflow-automation contexts, rather than purely conversational tasks.
Coding: Early independent evaluations show GLM 5.2 as the strongest open-weight coding model available, with reported scores of 81.0% on Terminal-Bench 2.1 and 62.1% on SWE-bench Pro. Its predecessor, GLM 5.1, had reached 77.8% on SWE-bench Verified.
Agentic abilities: The model is explicitly positioned as agent-first rather than chat-first function calling, tool use, browser automation, and multi-step API orchestration are treated as the primary design target, with conversational chat as a secondary use case.
Open-source status: Fully open under the MIT license, with no regional usage restrictions a deliberate contrast to closed, geographically gated frontier models.
API availability: Available via Zhipu's own GLM Coding Plan and a standalone API, plus third-party hosts such as OpenRouter and Hugging Face Inference Providers. Pricing through OpenRouter runs around $1.40 per million input tokens and $4.40 per million output tokens.
Supported languages: Strong coverage across Python, JavaScript, TypeScript, C++, Java, Go, Rust, and SQL, alongside multilingual natural-language support reflecting its Chinese-lab origin.
What is Claude?
Claude AI overview
Claude is Anthropic's family of large language models, available through claude.ai, the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. The current generally available flagship is Claude Opus 4.8, alongside Claude Sonnet 4.6 for everyday use and Claude Haiku 4.5 for fast, lightweight tasks. A more capable tier, Claude Mythos Preview, is being rolled out gradually to a limited set of trusted organizations under Anthropic's Project Glasswing rather than released broadly.
Claude Code
Claude Code is Anthropic's command-line agentic coding tool, built for tasks that go beyond single-function code completion repository-scale migrations, multi-file refactors, and long, multi-hour coding sessions. With Opus 4.8, Anthropic introduced "dynamic workflows," where Claude Code can plan a task and dispatch hundreds of parallel subagents that work independently and cross-check each other's output before reporting back.
Coding capabilities
According to Anthropic's published system card, Opus 4.8 scores 88.6% on SWE-bench Verified and 69.2% on SWE-bench Pro, both improvements over Opus 4.7 (87.6% and 64.3% respectively). On Terminal-Bench 2.1 it reaches 74.6%, trailing GPT-5.5's self-reported 83.4% though that GPT-5.5 number was produced through OpenAI's own Codex CLI harness rather than the shared public Terminus-2 harness used for Opus 4.8, which makes the two numbers not directly comparable.
Reasoning
Opus 4.8 posts 93.6 on GPQA Diamond, statistically tied with Opus 4.7 and Gemini 3.1 Pro, and leads on Humanity's Last Exam (HLE), a benchmark designed to stay unsaturated longer than GPQA.
Long context
Opus 4.8 supports a 1-million-token input context window with up to 128K tokens of output functionally matching GLM 5.2's context length, though GLM 5.2's slightly larger 131K output ceiling gives it a marginal edge for very long generated outputs.
Enterprise features
Claude ships with enterprise-grade access controls, audit logging, and availability across major cloud marketplaces (Bedrock, Vertex AI, Microsoft Foundry), plus a documented alignment and safety evaluation process published alongside every major release.
Best use cases
Multi-file refactors, large legacy codebase navigation, long agentic coding sessions, regulated-industry deployments that require an established compliance track record, and teams that need predictable, well-documented model behavior over raw price efficiency.
GLM 5.2 vs Claude
Category | GLM 5.2 | Claude Opus 4.8 | Edge |
|---|---|---|---|
Coding (SWE-bench Verified) | ~77.8% (GLM 5.1 baseline; 5.2 not yet officially published on this benchmark) | 88.6% | Claude |
Coding (SWE-bench Pro) | 62.1% | 69.2% | Claude |
Terminal/agentic tasks | 81.0% (Terminal-Bench 2.1) | 74.6% (Terminal-Bench 2.1, public harness) | GLM 5.2 |
Reasoning (Artificial Analysis Intelligence Index) | 51 | Not directly listed on the same index at publication time | GLM 5.2 (on this specific index) |
Instruction following | Strong, agent-tuned | Strong, with documented "explain before pivoting" behavior | Roughly even |
Long context | 1M input / 131K output | 1M input / 128K output | Roughly even |
Math | Solid, workflow-oriented | Strong, GPQA/HLE-leading | Claude |
Debugging | Capable, less third-party verification | Strong; 4x improvement in flagging its own code flaws (Anthropic's internal metric) | Claude |
Refactoring (large codebases) | Benefits from huge context, less proven at scale | Proven in production via Claude Code's dynamic workflows | Claude |
Tool use / function calling | Core design focus | Strong, slightly behind GPT-5.5 on shell-heavy CLI tasks | Roughly even |
Speed/latency | Competitive, helped by MoE sparsity | Fast mode now 2.5x speed at lower relative cost | Roughly even |
Accuracy on real-world long-horizon work (AA-Briefcase) | 1266 Elo | 1356 Elo (Opus 4.8) | Claude |
API pricing | ~$1.40 / $4.40 per million tokens (in/out) | $5 / $25 per million tokens (in/out) | GLM 5.2 |
Open-source availability | Full MIT license, self-hostable | Closed, API/cloud-only | GLM 5.2 |
Enterprise readiness | Emerging, limited track record | Established, multi-cloud, audited | Claude |
Security/access stability | No regional restrictions | Subject to export-control restrictions on newest tier | GLM 5.2 |
A caveat worth repeating: Zhipu did not publish an official, full benchmark suite at GLM 5.2's launch, leaning instead on infrastructure claims about the 1M context window. Most GLM 5.2 numbers above come from independent trackers and model-card aggregators rather than a single authoritative source, so treat them as directionally useful rather than exact.
Coding Benchmarks
SWE-bench Verified
What it measures: Resolution rate on 500 human-validated real GitHub issues, each requiring an actual code patch that passes the original test suite.
Winner: Claude Opus 4.8 (88.6%), based on currently published numbers. GLM 5.2 has not had an official Verified score published as of this writing; its predecessor GLM 5.1 scored 77.8%.
Real-world meaning: Verified is a strong general signal for "can this model fix a real, scoped bug," but it's increasingly saturated; most frontier models now cluster in the 80–90% range, so small differences matter less than they used to.
Limitations: Verified has known contamination concerns; some training sets may overlap with benchmark tasks, inflating scores. Treat any single Verified number as a rough indicator, not gospel.
SWE-bench Pro
What it measures: A harder, less-contaminated variant pulling from actively maintained repositories with multi-file diffs and held-out commercial tasks the public can't see in advance.
Winner: Claude Opus 4.8 (69.2%) over GLM 5.2 (62.1%).
Real-world meaning: This is the closest proxy for production engineering multi-file changes, architectural understanding, no memorization shortcuts. Claude's ~7-point lead here is the most credible evidence in this entire comparison that Claude still leads on raw coding capability.
Limitations: Scaffold differences between vendor-run and standardized-harness scores (like Scale's SEAL leaderboard) can shift results by 15–30 points, so cross-vendor SWE-bench Pro comparisons should be read with care.
HumanEval and MBPP
What they measure: Function-level code generation correctness on relatively small, self-contained problems.
Winner: Both models perform near the ceiling on these older benchmarks; neither has a meaningful published advantage, and the field broadly treats HumanEval and MBPP as largely saturated and less diagnostic than they were two years ago.
LiveCodeBench
What it measures: Contamination-resistant coding problems sourced continuously from recent competitive programming contests, reducing the chance a model has memorized the answer.
Winner: No comprehensive, directly comparable GLM 5.2 vs Claude Opus 4.8 LiveCodeBench numbers were publicly available at the time of writing — a genuine evidence gap worth flagging rather than papering over.
Aider Polyglot
What it measures: Real-world, multi-language code-editing accuracy using the Aider coding assistant's diff-based editing format.
Winner: Not yet independently published for GLM 5.2 as of this writing; Claude models have historically scored competitively on this benchmark in prior generations.
Codeforces
What it measures: Competitive programming problem-solving under contest-style constraints.
Winner: Insufficient independent data on GLM 5.2 specifically; avoid trusting any single-source Codeforces claim from either camp without a verifiable methodology.
Agent benchmarks (Terminal-Bench, AA-Briefcase)
What they measure: Multi-step, tool-using agentic task completion — closer to "can this model actually do a job" than "can it answer one question."
Winner: Mixed. GLM 5.2 leads on Terminal-Bench 2.1 (81.0% vs. 74.6%), but on Artificial Analysis's more demanding AA-Briefcase benchmark — built around multi-week, multi-document knowledge work — Claude's higher tiers led clearly, with Opus 4.8 at 1356 Elo versus GLM 5.2's 1266 Elo. Notably, even the top model on AA-Briefcase satisfied every rubric criterion on only 3% of tasks, which says more about how hard real agentic work still is than about either model's polish.
Does GLM 5.2 Really Beat Claude?
Separating hype from reality
The "GLM 5.2 beats Claude" narrative is mostly built on three things: the Terminal-Bench 2.1 lead, the dramatically lower price, and the political timing of the export-control suspension affecting Claude's newest tier. All three are real. None of them amount to GLM 5.2 being a better coding model across the board.
Marketing claims: Zhipu's own launch messaging emphasized infrastructure achievements (1M context, IndexShare attention) over head-to-head benchmark tables notably, the company didn't publish a full official benchmark suite at launch, which independent observers flagged as unusual for a release positioned this aggressively.
Independent evaluations: Artificial Analysis's Intelligence Index placed GLM 5.2 at the top of all open-weight models (score of 51), ahead of Gemini 3.1 Pro (46) on that specific index, a genuinely impressive result for an open model, but that index doesn't isolate coding ability specifically.
Community testing: Reaction has been strong but not uncritical. Multiple practitioners described GLM 5.2 as comparable to Claude Opus 4.8 and GPT-5.5 "for their use," while explicitly noting the absence of vision/multimodal support as a real limitation for mixed workflows.
Developer feedback, GitHub, and Reddit discussions: Sentiment skews toward "impressive for an open model at this price" rather than "outright better than Claude." The recurring theme in developer commentary is that GLM 5.2 closes the gap enough to be a serious default for cost-sensitive or self-hosted use cases, not that it surpasses Claude on the hardest coding tasks.
Strengths of GLM 5.2
Genuinely large, usable 1M-token context window
MIT license with no regional restrictions meaningful for teams worried about access stability
Roughly one-sixth the API cost of Claude Opus 4.8
Strongest open-weight performer on agentic/terminal benchmarks
Self-hostable for compliance-sensitive or air-gapped environments
Weaknesses of GLM 5.2
No official, comprehensive benchmark suite at launch independent numbers fill the gap, with inconsistent methodology
No vision/multimodal support at launch
Trails Claude Opus 4.8 on SWE-bench Verified and SWE-bench Pro, the two most production-relevant coding benchmarks
Newer ecosystem; less enterprise track record and fewer third-party security audits
Self-hosting at full precision requires serious hardware (multiple H100-class GPUs)
New Independent Research: What Changed After Launch (June 2026 Updates)
The benchmark picture kept moving in the weeks after GLM 5.2's launch, as more labs, security teams, and independent testers ran their own head-to-head evaluations. Here's what the newest research actually found.
Z.ai published a full scorecard — and the gap is closer than expected
On June 16, 2026, Z.ai released a complete benchmark table comparing GLM 5.2 directly against Claude Opus 4.8 across 19 reasoning, coding, and agentic evaluations. Opus 4.8 still wins the majority of categories, with its widest leads on long-horizon software engineering work: NL2Repo (69.7 vs. 48.9), SWE-Marathon (26.0 vs. 13.0), and Tool-Decathlon (59.9 vs. 48.2).
But GLM 5.2 closes to within a single point on FrontierSWE (74.4 vs. 75.1) and MCP-Atlas (76.8 vs. 77.8), and it outright wins on AIME 2026, IMOAnswerBench, and Terminal-Bench 2.1 under its own best-performing harness. The practical read: Claude still holds the ceiling on multi-hour, repository-scale engineering tasks, while GLM 5.2 is essentially tied on shorter agentic and tool-use evaluations.
A security firm found GLM 5.2 beat Claude Code on real vulnerability detection — with caveats
Application-security company Semgrep ran GLM 5.2, Claude Code, and several other models against a benchmark for detecting IDOR (Insecure Direct Object Reference) vulnerabilities — access-control bugs that are notoriously hard for both static analyzers and LLMs to catch because there's no single "dangerous function" to flag, only a missing permission check. With no special scaffolding, just a prompt and the codebase, GLM 5.2 scored 39% F1 versus Claude Code's 32%, at roughly $0.17 per real vulnerability found.
The important caveat, which Semgrep itself emphasized: this was a deliberately unscaffolded test. Their own purpose-built detection pipeline, running GPT-5.5 or Opus 4.8 behind a custom harness that pre-identifies application endpoints, still scored far higher (53–61% F1) than any bare-prompt model. The harness mattered more than the model swap. Semgrep's stated conclusion was narrower than the "GLM 5.2 beats Claude" headlines that followed it:
among models given nothing but a prompt, the strongest open-weight option is no longer an obvious underdog — not that open weights have caught up to closed frontier models generally.
The discussion thread on Hacker News reflected that same split: some commenters pointed out the comparison pitted GLM against an unscaffolded Claude Code run rather than Claude's strongest configuration, while others reported genuinely strong personal results using GLM 5.2 for vulnerability research, including that it was less likely to refuse security-related tasks than Claude.
An agentic coding head-to-head found the two models statistically tied on quality
Developer tooling researcher Aiswarya Sankar ran GLM 5.2 and Claude Opus head-to-head inside the same Claude Code harness on 45 terminal-bench style engineering tasks, with binary pass/fail grading from each task's own hidden test suite. The result: both models solved exactly 25 of 45 tasks, and agreed on the outcome of 43 of the 45 — a near-total overlap in capability on this specific test set. The two diverged only on cost and process.
GLM 5.2 took roughly twice as many turns and more tokens to reach the same answers, since it explores and backtracks more than Opus. But with prompt caching enabled, GLM 5.2's actual spend landed at about 46% of Opus's cost for the identical 25/45 result — and even without caching, it still came in around 10% cheaper.
UI and design generation tests show a split decision, not a sweep
A side-by-side comparison from MindStudio testing both models on 3D scenes, dashboards, landing pages, and mini-games found genuinely mixed results rather than a win for either side. GLM 5.2 produced dashboard and component-scaffolding code that was "near-equivalent" in quality to Opus 4.8 at a fraction of the cost, making it the practical choice for high-volume, structure-heavy UI work. Claude Opus 4.8 pulled ahead on tasks requiring creative visual judgment — 3D scene composition, landing-page design taste, and mini-game logic with fewer edge-case bugs — and was described as "not close" ahead on agentic, multi-step coding where self-correction matters.
Separately, Design Arena's public blind-voting leaderboard for single-turn HTML website generation showed GLM 5.2 overtaking Claude Fable 5 for the top overall spot — notable partly because GLM 5.2 has no vision capability at all, and achieved this using consistent, high-performing design templates rather than broader creative range. Design Arena's own analysis was careful to note that winning a website-generation leaderboard doesn't establish broader reasoning parity.
One independently run test built the same 3D platformer game in both Claude Code (Opus 4.8) and a GLM 5.2 harness from identical prompts. Opus finished in about half the wall-clock time with a cleaner result and only edge-case bugs;
GLM 5.2 took over twice as long and shipped a rougher build with more fundamental issues — a gap the testers attributed partly to GLM 5.2's lack of vision support, since it couldn't visually verify its own output by looking at a screenshot the way Opus could, and instead resorted to checking raw pixel data programmatically. GLM 5.2's run still cost roughly a fifth as much.
Community and analyst sentiment: genuine progress, not parity
AI analyst commentary (notably from the Interconnects newsletter) framed GLM 5.2 as the most significant open-weight coding release since DeepSeek R1, closing what had been a roughly 6–9 month capability gap between leading U.S. closed labs and Chinese open labs to about 6.8 months measured from Claude Opus 4.5's release. That same analysis was explicit that this is a narrowing of the gap, not a closing of it.
A widely shared Medium piece asking "Is China's free GLM 5.2 really better than Claude?" reached a similar verdict in its own words: no, it does not beat Claude on most things, but it's close enough, cheap enough, and open enough that for a large share of real-world work, the gap stops mattering.
Real Coding Test
Independent and vendor-published results across common languages paint a consistent picture: Claude Opus 4.8 tends to hold an edge on multi-file, architecture-aware tasks, while GLM 5.2 is highly competitive on single-file and script-level generation, often at a fraction of the cost.
Python: Both models handle standard scripting and data-processing tasks well. Claude shows an edge on tasks requiring cross-file dependency tracking.
JavaScript / TypeScript: GLM 5.2 has demonstrated strong front-end generation in published Zhipu demos (interactive UI components, games built with Three.js). Claude Opus 4.8 tends to produce more consistent type-safety and fewer runtime edge-case bugs in larger TypeScript codebases.
Rust: Limited independent head-to-head data exists; Claude's stronger SWE-bench Pro performance suggests an advantage on Rust's stricter compiler-driven correctness requirements, but this hasn't been benchmarked in isolation publicly.
Go: Both models handle idiomatic Go reasonably well for service-level code; differentiation here is thin in available public testing.
C++: Memory-management-heavy C++ refactors favor models with stronger multi-file reasoning — an area where Opus 4.8's SWE-bench Pro lead is most relevant.
Bug fixing: This is where SWE-bench Pro's 7-point Claude advantage is most directly applicable — locating, understanding, and correctly patching a real bug across multiple files without breaking adjacent functionality.
SQL: Both models produce reliable SQL for standard query and schema tasks; this is not a strong differentiator between them based on currently available evidence.
The honest takeaway: for short, well-scoped tasks in common languages, the practical difference between the two models is often smaller than the price difference. For long, multi-file, architecture-sensitive work, Claude's benchmark lead translates into a real, measurable advantage.
Pros & Cons
GLM 5.2
Pros
Dramatically cheaper per million tokens
MIT-licensed, fully open weights
1M-token context with strong agentic tuning
No regional access restrictions
Strong Terminal-Bench performance
Cons
Trails on SWE-bench Verified and Pro
No official full benchmark suite published at launch
No vision/multimodal support
Less mature enterprise tooling and audit history
Heavy hardware requirements for full self-hosting
Claude
Pros
Leads on SWE-bench Verified and SWE-bench Pro
Mature Claude Code agentic workflows with parallel subagents
Established enterprise deployment across major clouds
Documented alignment and safety evaluation process
Strong multimodal (vision) support
Cons
Significantly more expensive per million tokens
Closed weights, cloud/API dependent
Newest tier (Fable 5/Mythos 5) currently restricted for foreign users under export controls
No self-hosting option
Who Should Use GLM 5.2?
Open-source developers who want full control over weights and fine-tuning
Researchers benchmarking architecture innovations like sparse long-context attention
Budget-conscious teams running high-volume inference where per-token cost dominates the decision
Local/on-prem deployment scenarios, especially in regulated or air-gapped environments
Startups that need frontier-adjacent capability without frontier-level API bills
Who Should Use Claude?
Professional developers working on production codebases where correctness on hard, multi-file bugs matters most
Teams managing large, legacy codebases that benefit from Claude Code's dynamic, parallel-subagent workflows
Enterprises that need established cloud-marketplace deployment (Bedrock, Vertex AI, Microsoft Foundry) and audited safety documentation
Production coding pipelines where the cost of a wrong patch outweighs the API cost difference
Agentic workflows requiring vision/multimodal input alongside code generation
Best AI Coding Assistant in 2026
Students: GLM 5.2 — low cost, generous context, good for learning and experimentation
Freelancers: Either, depending on client codebase size; GLM 5.2 for cost-sensitive solo work, Claude for client work requiring reliability on legacy code
Agencies: Claude, for consistent multi-project reliability and enterprise client expectations
Startups: GLM 5.2 early on for cost control, with a planned migration path to Claude as codebases and reliability requirements grow
Large companies: Claude, given enterprise tooling, audit trails, and the SWE-bench Pro advantage on real engineering work
Researchers: GLM 5.2, for the ability to inspect, fine-tune, and modify open weights
Open-source contributors: GLM 5.2, for license compatibility and self-hosting flexibility
Frequently Asked Questions
Not consistently. GLM 5.2 leads on Terminal-Bench 2.1 and on Artificial Analysis's open-model Intelligence Index, but Claude Opus 4.8 leads on SWE-bench Verified and SWE-bench Pro — the two benchmarks most directly tied to real-world software engineering accuracy.
Yes. GLM 5.2 is released under the MIT license with open weights and no regional usage restrictions, making it freely usable for commercial and research purposes.
For long, multi-file agentic sessions and production codebase work, current benchmark data favors Claude Code with Opus 4.8. GLM 5.2 is competitive on terminal-style agentic tasks but trails on the harder, real-world SWE-bench Pro evaluation.
Through providers like OpenRouter, GLM 5.2 runs roughly $1.40 per million input tokens and $4.40 per million output tokens, compared to Claude Opus 4.8's $5 and $25 — making GLM 5.2 roughly five to six times cheaper per token.
Yes, the open weights support self-hosting, though full-precision production throughput requires substantial hardware, on the order of multiple H100-class 80GB GPUs.
Yes, Claude Opus 4.8 supports a 1-million-token input context with up to 128K tokens of output, functionally comparable to GLM 5.2's 1M input / 131K output window.
A US government export-control directive in June 2026 required Anthropic to suspend foreign access to its newest tier, Claude Fable 5 and Claude Mythos 5. This does not affect Claude Opus 4.8, Sonnet 4.6, or Haiku 4.5, which remain broadly available.
Yes, GLM 5.2 has shown strong front-end and interactive UI generation capability in published demos, though Claude tends to show fewer edge-case bugs in larger, multi-file TypeScript codebases according to available benchmark trends.
SWE-bench Pro draws from actively maintained repositories with multi-file diffs and held-out commercial tasks, making it far more resistant to memorization than the original, increasingly saturated SWE-bench Verified set — making it a better proxy for real production coding ability.
No. As of its June 2026 launch, GLM 5.2 does not include vision/multimodal support, which several early testers flagged as its most significant practical limitation versus closed frontier models.
Claude currently has the stronger enterprise track record, with established availability on Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry, along with published safety and alignment documentation per release.
Independent reporting describes it as a "fully usable" 1M context, aided by the model's IndexShare sparse-attention architecture designed specifically to keep long-context inference costs from exploding — though independent long-context degradation testing is still limited.
If you're not currently hitting context-window limits or coding-accuracy issues with Claude Code, the switching cost (re-tuning prompts, re-running evals, reconfiguring tooling) likely outweighs the savings. If cost or self-hosting requirements are the actual bottleneck, GLM 5.2 is worth a structured pilot.
GLM 5.2, by a wide margin. It delivers competitive agentic and terminal-task performance at roughly one-sixth the API cost of Claude Opus 4.8.
Possibly. GLM 5.1 to 5.2 already showed meaningful gains on internal app-dev tasks and agentic benchmarks. Given the pace of releases from both labs in 2026, the gap is worth re-checking with each new model generation rather than assuming it's fixed.
In one specific, narrow test, yes: security firm Semgrep found GLM 5.2 scored higher than Claude Code on detecting IDOR access-control bugs when both were given a bare prompt with no special tooling (39% F1 vs. 32%). Semgrep itself was careful to frame this as evidence that the harness around a model often matters more than the model itself, not as proof that open-weight models have overtaken Claude generally — their own purpose-built detection pipeline using Opus 4.8 still scored far higher than either bare-prompt result.
On one public benchmark, yes — Design Arena's blind-voting leaderboard for single-turn HTML website generation, where GLM 5.2 overtook Claude Fable 5 for the top spot despite having no vision capability. That result reflects GLM 5.2's consistent design-template approach more than broader creative or reasoning superiority, and GLM 5.2 ranks lower on other Design Arena categories like 3D design and UI components.
Conclusion
GLM 5.2 does not beat Claude across the board, and any headline claiming otherwise is oversimplifying selective benchmark results. On the two coding benchmarks most tied to real production engineering — SWE-bench Verified and SWE-bench Pro — Claude Opus 4.8 holds a clear, currently verifiable lead, a lead that Z.ai's own published scorecard confirms widens further on long-horizon, repository-scale tasks like NL2Repo and SWE-Marathon.
GLM 5.2 does win outright on Terminal-Bench 2.1, on Artificial Analysis's open-model Intelligence Index, on Design Arena's website-generation leaderboard, and decisively on price and openness. In at least one narrow, independently run agentic test, the two models tied exactly on task-solving accuracy, differing only in cost and speed — and in a security-focused benchmark, GLM 5.2 beat an unscaffolded Claude Code on vulnerability detection, though the same researchers found a properly harnessed Opus 4.8 still came out ahead.
What GLM 5.2 represents isn't a Claude-killer — it's the first open-weight model close enough to a closed frontier model that the comparison is worth having at all, and arguably the most significant open-weight coding release since DeepSeek R1.
For teams prioritizing cost, self-hosting, or access independence, GLM 5.2 is a legitimate, well-built option. For teams whose primary cost is engineering time lost to a wrong patch on a hard, multi-file bug, Claude Opus 4.8's benchmark lead still translates into real-world value. The honest verdict, echoed by nearly every independent tester who's actually run both: GLM 5.2 beats Claude in selected benchmarks and specific task types, not in coding capability overall — and that distinction matters more than any single headline number.
Schema Markup
FAQ Schema
json
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Does GLM 5.2 really beat Claude in coding benchmarks?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Not consistently. GLM 5.2 leads on Terminal-Bench 2.1 and Artificial Analysis's open-model Intelligence Index, but Claude Opus 4.8 leads on SWE-bench Verified and SWE-bench Pro, the benchmarks most tied to real-world software engineering accuracy."
}
},
{
"@type": "Question",
"name": "Is GLM 5.2 open source?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Yes. GLM 5.2 is released under the MIT license with open weights and no regional usage restrictions."
}
},
{
"@type": "Question",
"name": "How much cheaper is GLM 5.2 than Claude?",
"acceptedAnswer": {
"@type": "Answer",
"text": "GLM 5.2 costs roughly $1.40 per million input tokens and $4.40 per million output tokens, compared to Claude Opus 4.8's $5 and $25, making it five to six times cheaper per token."
}
},
{
"@type": "Question",
"name": "Can I self-host GLM 5.2?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Yes, GLM 5.2's open weights support self-hosting, though full-precision production throughput requires substantial hardware, such as multiple H100-class GPUs."
}
},
{
"@type": "Question",
"name": "Does Claude support a 1-million-token context window?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Yes, Claude Opus 4.8 supports a 1-million-token input context with up to 128K tokens of output."
}
}
]
}
Article Schema
json
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "GLM 5.2 vs Claude: Does GLM 5.2 Really Beat Claude in Coding Benchmarks?",
"description": "A research-backed comparison of GLM 5.2 and Claude AI across coding benchmarks, pricing, architecture, and real-world developer use cases.",
"datePublished": "2026-06-29",
"dateModified": "2026-06-29",
"author": {
"@type": "Person",
"name": "AI Research & Engineering Desk"
},
"publisher": {
"@type": "Organization",
"name": "Your Publication Name"
},
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://example.com/glm-5-2-vs-claude-coding-benchmarks"
}
}
Breadcrumb Schema
json
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "Home",
"item": "https://example.com/"
},
{
"@type": "ListItem",
"position": 2,
"name": "AI Tools",
"item": "https://example.com/ai-tools/"
},
{
"@type": "ListItem",
"position": 3,
"name": "GLM 5.2 vs Claude",
"item": "https://example.com/glm-5-2-vs-claude-coding-benchmarks"
}
]
}