I shipped a feature in four hours last year that should have taken two days. The copilot wrote most of it. I felt like a genius until three weeks later, when that same feature took down our staging environment because of a null check that never existed. It wasn't a bug in the traditional sense; it was AI-generated code doing exactly what I asked, just not what I actually needed.

That gap between "it works" and "it's right" is where technical debt lives, and AI-generated code has become one of the fastest ways to accumulate it. This isn't an anti-AI rant. I use AI coding tools every single day. But after two years of watching teams adopt them and cleaning up after a few I've noticed patterns that most "AI will replace developers" articles conveniently skip. It also turns out the data backs up what a lot of us have been feeling in our guts.
The Numbers Are Now In, and They're Not Subtle
For a while this whole topic was vibes and anecdotes. That's changed. Several independent research efforts published over the past year have quantified exactly what's happening to codebases as AI-generated code scales, and the picture is remarkably consistent across all of them.
GitClear analyzed 211 million changed lines of code from 2020 through 2024 across private repositories and large open-source projects. The findings: copy-pasted code rose from roughly 8% to over 12% of all changed lines, and for the first time in the dataset's history, copy-pasted code exceeded code that had been "moved," meaning refactored into reusable form. Refactoring activity, meanwhile, dropped from around a quarter of all changes in 2021 to under 10% by 2024. Code reuse, in other words, is dying at exactly the moment code volume is exploding.

Security firm Ox Security looked at this from a different angle. They analyzed 300 open-source projects, half of them AI-generated in whole or part, and identified recurring anti-patterns. Comment overload, textbook-pattern fixation, avoidance of refactoring, and over-engineered edge-case handling each showed up in 80% to 100% of AI-generated code samples. Their framing stuck with me: AI-generated code reads like the work of an army of talented juniors — technically functional, structurally unsupervised.
SonarQube's 2026 State of Code survey put a number on the trust gap directly: 53% of developers say AI generates code that looks correct but hides defects, and 40% say AI-generated duplication has measurably increased their technical debt. The same survey found 88% of developers report at least one negative technical-debt impact from AI tools — and, in the same breath, 93% report at least one positive impact, mostly around documentation and legacy-code navigation. It's not that AI is bad. It's that it cuts both ways, hard, in both directions at once.
What Technical Debt Actually Means (Not the Textbook Version)
Ward Cunningham coined the term technical debt back in 1992 to describe the tradeoff between shipping fast and writing clean code. The metaphor holds: you borrow time now, and you pay it back later with interest.
Here's the part people miss. Debt isn't bad code. Debt is code you don't fully understand anymore, written under assumptions nobody wrote down, that you now have to change without breaking something else.
AI-generated code accelerates this in a specific way that a 2026 academic study out of Missouri University of Science and Technology put a name to: GenAI-Induced Self-Admitted Technical Debt, or GIST. The researchers combed through thousands of code comments across GitHub repos that referenced AI tools, then cross-referenced them against classic debt markers like TODO and FIXME. The pattern they found: developers most often flag AI code for incomplete implementation and deferred testing, not design flaws. In other words, the code often looks structurally fine; the shortcuts are in verification, not architecture.
The Problem, Stated Plainly
When you write code yourself, even bad code, you carry a mental model of why you made each decision. When an AI writes it, that mental model doesn't exist, not in your head, and not really in the model's either.
You get code that:
Passes the happy path but ignores edge cases
Uses outdated patterns pulled from training data
Duplicates logic instead of reusing existing utilities
Looks clean but hides subtle logical errors
Solves the literal prompt, not the actual business problem
None of these show up in a quick review. They show up three sprints later, in production, at 2 a.m. a scenario one developer described so precisely on Dev.to that it's worth stealing: debugging code you technically own but didn't write, trying to reverse-engineer the reasoning of a model that never had any reasoning to begin with.
Real-World Developer Scenarios
Scenario 1: The Auth Bug Nobody Caught
A startup I consulted for used ChatGPT to scaffold a password reset flow. It worked in testing. It also, quietly, didn't invalidate the previous reset token after use meaning old reset links stayed valid indefinitely. Nobody caught it in code review because the code looked correct. It read like something out of a tutorial, because it basically was.
Scenario 2: The Duplicate Utility Sprawl

A mid-size SaaS team let multiple engineers use Copilot independently for six months. When they finally audited the codebase, they found seven different date-formatting functions, each subtly different, each generated in a separate PR because the AI didn't know the other six existed. This is exactly the pattern GitClear's data captures at industry scale one developer writing about his own six months of daily Claude Code use put a real number on it: 47 AI-generated interfaces in a 15-entity project, where the actual need for polymorphism existed in three cases.
Scenario 3: The "Fixed" Bug That Wasn't
An engineer asked an AI tool to fix a race condition in a queue processor. The AI added a setTimeout delay. The bug disappeared in testing. It came back in production under load, because a timeout isn't a fix, it's a bet that the timing will hold, and production traffic doesn't respect bets. This is a close cousin of a pattern some developers call "silent degradation" models that would rather swallow an error and return an empty value than surface the actual problem.
These aren't edge cases. They're the default outcome when AI output gets merged without someone owning the "why."
Why This Problem Exists
1. AI Models Optimize for Plausibility, Not Correctness
Large language models predict the next most likely token based on patterns in training data. That's genuinely useful for boilerplate. It's dangerous for anything requiring actual reasoning about your system's specific constraints, because the model has never seen your system. As one experienced Symfony and Go developer put it after months of daily Claude Code use: the model doesn't write bad code on purpose, it writes code that statistically resembles what it saw in training and plausible isn't the same thing as correct.
2. Context Windows Don't Equal Codebase Understanding
Even with large context windows, most AI coding tools see a slice of your repo, not the tribal knowledge behind it, the outage from 2023, the vendor limitation nobody documented, the reason that one function looks weird on purpose. LeadDev's coverage of the GitClear research quotes GitClear's CEO warning that if teams keep measuring developer output by commit count or lines added, AI-driven maintainability decay will keep spreading.
3. Developers Trust Output That Looks Clean

Clean formatting reads as correct. Consistent naming reads as intentional. Neither actually verifies logic. Reviewers demonstrably spend less time scrutinizing AI-generated pull requests than human-authored ones, precisely because the formatting looks like it was written by someone competent, a dynamic engineer summed up as a trap door with a nice rug over it.
4. Review Fatigue Sets In Fast
When most of a PR is AI-generated and looks fine, reviewers start skimming instead of reasoning. Google's 2024 DORA research found a real tradeoff here: a 25% increase in AI usage sped up code reviews and improved documentation, but also produced roughly a 7% drop in software delivery stability. Speed and stability moved in opposite directions.
5. Nobody "Owns" the Decision
In human-written code, there's a person who made the tradeoff and can explain it later. With AI-generated code, ownership becomes fuzzy. Who do you ask why this approach was chosen? Nobody. That's the debt. Some engineers have started calling this ownership debt the point where a developer's instinct when something breaks shifts from "let me debug this" to "let me try regenerating it with a different prompt." That's not debugging anymore. That's gambling with extra steps.
Practical Solutions That Actually Work
I'm not going to tell you to "review AI code carefully." Everyone says that and it changes nothing because reviewing everything with equal scrutiny doesn't scale. Here's what's actually worked on teams I've worked with, backed up by what's working elsewhere too.
Require a One-Sentence "Why" Before Anything Merges
If an engineer can't explain, in their own words, in the PR description, why the AI's approach is correct it doesn't merge. Not "AI generated retry logic." Something like: this uses exponential backoff because the upstream API rate-limits after three rapid retries. This single rule catches an enormous share of the auth-bug and race-condition category of mistakes, because it forces someone to actually read the logic instead of the formatting.
Force a Real Human Touch on Every AI-Generated Block
A renamed variable doesn't count. Require at least one meaningful modification: an added edge case, a refactored condition, a different error-handling approach before an AI-generated block can merge. You can't change something you don't understand, so the act of modifying it becomes a forcing function for actually comprehending it.
Run AI-Generated Code Through Static Analysis Every Time
Tools like SonarQube, ESLint, or Semgrep won't catch business logic errors, but they reliably catch the boring stuff: unhandled exceptions, unused variables, security anti-patterns, and increasingly, duplication detection tuned specifically for AI-generated clones.
Ban AI-Written Tests for AI-Written Code
This one surprises people. If an AI writes both the implementation and the test, the test often just validates whatever the AI assumed, not what's actually correct one developer described finding a test suite sitting at 94% coverage that didn't catch a single real business-logic error, because every test just verified that a method called another method with the expected arguments. Write tests independently, ideally before you even see the AI's implementation.
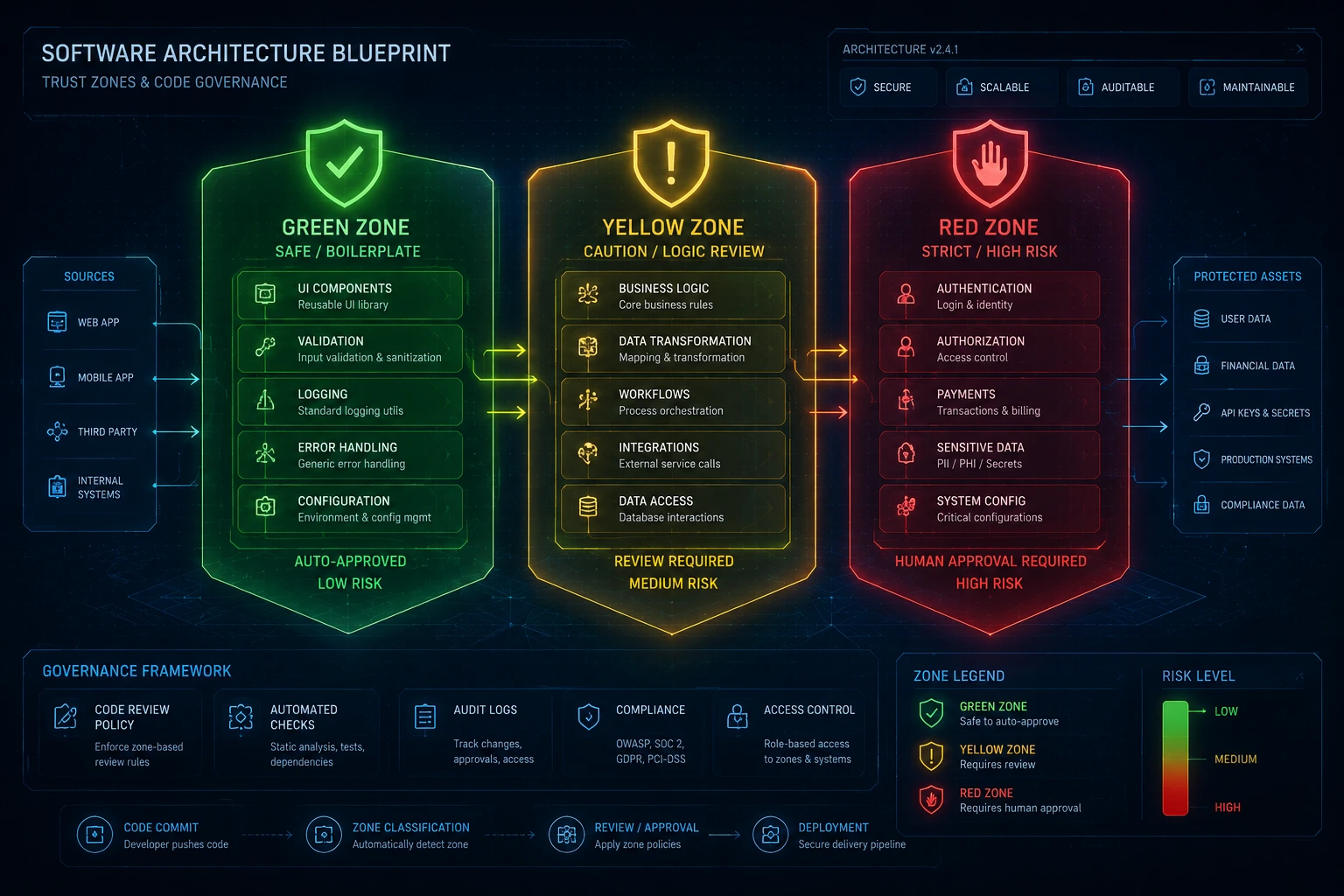
Set Zones, Not Bans
Don't ban AI tools outright, that's a losing battle. Instead, define where AI gets free rein and where it doesn't: green zone for boilerplate, scaffolding, and utility functions; yellow zone for business logic and API integrations, which get extra review; red zone humans only for authentication, payments, and core algorithms where a bug becomes an incident report instead of a headline.
Keep a "Debt Log" for AI-Assisted PRs
A simple shared doc where engineers flag "this was AI-assisted and I'm not 100% sure about X" takes two minutes and saves entire sprints later. It turns invisible debt into visible, trackable debt which is the whole game.
Expert Insights
The consistent theme across every serious study on this, from GitClear's 211-million-line analysis to Ox Security's "Army of Juniors" report to SonarQube's developer survey, is that AI tools measurably speed up code generation without measurably speeding up code comprehension. GitClear's CEO, in comments to LeadDev, was candid that even he rarely thought about the long-term costs while he was in the moment of shipping with AI tools.
The Ox Security report goes a step further and argues the industry needs a new developer posture entirely treating AI as implementation support while humans focus on architecture and judgment calls, because by their reading, manual code review alone can no longer keep pace with how fast AI-generated code reaches production.
AI-Generated Code vs. Human-Written Code
Factor | AI-Generated Code | Human-Written Code |
|---|---|---|
Speed to first draft | Very fast | Slower |
Context awareness | Limited to prompt/context window | Full tribal knowledge |
Edge case handling | Often incomplete, or over-engineered for edge cases that don't matter | Depends on developer, usually more deliberate |
Consistency across codebase | Low without active governance (GitClear found copy-paste now exceeds refactored code) | Higher with team conventions |
Explainability | Weak — "why" often unclear even to the person who merged it | Strong — decisions can be traced |
Best use case | Boilerplate, scaffolding, repetitive patterns | Core business logic, architecture decisions |
Pros and Cons of AI-Generated Code
Pros | Cons |
|---|---|
Dramatically faster boilerplate and scaffolding | Encourages shallow review due to clean formatting |
Great for learning unfamiliar syntax or APIs | 53% of developers say it produces code that looks correct but hides defects (SonarQube, 2026) |
Reduces repetitive typing fatigue | Duplication is up sharply since 2020 by lines changed (GitClear) |
Genuinely improves documentation for messy legacy systems | Ownership and reasoning behind code become unclear |
Lowers the barrier for prototyping ideas quickly | Refactoring activity has dropped by more than half since 2021 (GitClear) |
Callout: The Real Cost Technical debt from AI code rarely shows up as a bug ticket. It shows up as "we're afraid to touch this file" six months later. That fear is the interest payment.
Common Mistakes Teams Make
Accepting suggestions without reading the full function — just the first few lines that look right.
Letting AI generate tests for AI-generated code — a closed loop that validates nothing.
Skipping documentation because "the code is self-explanatory" — it isn't, six months from now.
Using AI for architecture decisions — it has no concept of your team's long-term roadmap or constraints.
Measuring success by lines of code shipped or PRs merged — instead of by defects found post-merge or how confidently your team can modify what it already has.
Best Practices Going Forward
Use AI for scaffolding and boilerplate, not for core business logic or security-sensitive code.
Pair every AI-assisted PR with an explicit reviewer checklist that includes a duplication check, not a general "looks good."
Keep a shared internal style guide the AI tool can reference, reducing pattern drift across the team.
Run periodic codebase audits specifically looking for AI-introduced duplication GitClear's data suggests most teams are underestimating how much of this exists.
Track what percentage of your merged code is AI-assisted. Most teams guess low; the real number is often far higher than expected.
Treat AI output as a starting point for a conversation, not a finished deliverable.
Where This Is Heading
AI coding tools are getting better at reasoning over larger codebases, and tools with deeper repo-level context are already reducing some of the "it doesn't know what already exists" problem. That will help with duplication.
It won't fix the ownership problem. Even a model with perfect codebase context still can't tell you why your team chose a particular tradeoff in 2022, because that knowledge often isn't written down anywhere the model can read. SonarQube's research frames the way forward as a "vibe, then verify" culture that lets developers move fast and experiment, but back it with deterministic, automated verification rather than hoping review catches everything. Their data shows teams already doing this see meaningfully better outcomes on both code quality and rework cost.
Expect more teams to formalize "AI code review checklists" the same way they formalized security checklists a decade ago. It's the same shape of problem: something new introduced risk faster than the existing process could absorb it, so the process had to catch up.
Actionable Takeaways
Review AI-generated code with the same scrutiny as a junior developer's first PR.
Require a one-sentence justification, in the developer's own words, for any AI-suggested logic before merging.
Never let the same tool write both the implementation and its tests.
Run static analysis with duplication detection on every AI-assisted PR without exception.
Track what share of your codebase is AI-generated and how often it needs revision within two weeks of merging that gap is a leading indicator of debt.
Reserve AI tools for boilerplate and scaffolding; keep authentication, payments, and core algorithms in human hands.

Conclusion
AI-generated code isn't inherently worse than human-written code; it's just faster to produce and easier to trust than it should be. That combination is exactly what technical debt needs to grow quietly, and the research now backs up what a lot of engineers have been feeling for the past two years: duplication is up, refactoring is down, and the gap between "it works" and "someone understands why" keeps widening. The fix isn't banning AI tools.
It's building the review habits, ownership, and documentation discipline that make sure speed doesn't quietly turn into six months of code nobody wants to touch.
The teams getting real value out of AI coding tools right now aren't the ones generating the most code. They're the ones asking "why" before they hit merge.
FAQ
Not always. Debt accumulates when AI output is merged without review, documentation, or a clear understanding of why the approach was chosen. SonarQube's 2026 survey found 93% of developers also report at least one positive impact on technical debt, mostly around documentation and legacy-code navigation, so used carefully, it can cut both ways.
Trusting clean formatting as a proxy for correctness. AI-generated code almost always looks polished, which makes reviewers skim instead of scrutinizing logic — research shows reviewers genuinely spend less time on AI-generated PRs than human-written ones.
They catch syntax issues, security anti-patterns, and increasingly, duplication across files that a single PR-scoped human review would never spot. They generally can't catch business logic errors, which is why human review still matters most.
Neither is inherently worse. The risk comes from volume and speed — some analyses put AI-era code generation at roughly 10 to 50 times faster than human coding, which means unreviewed debt accumulates far faster if the process doesn't scale with it.
Avoid this where possible. If the same model writes both the implementation and its tests, the tests tend to validate the AI's assumptions rather than actual correctness — a well-documented failure mode where coverage numbers look great and catch nothing real.
Look for duplicated utility functions, inconsistent error handling patterns across similar features, excessive comments (a signal found in 80-90% of AI-generated code per Ox Security's research), and any file the team is reluctant to modify without extensive testing.
Yes, with the same review rigor applied to any production code — tests written independently, static analysis, and a clear owner who can explain the logic in their own words before it ships.
It can inflate lines-of-code shipped while quietly increasing defect rates post-merge. GitClear's 211-million-line study found code churn — lines revised within two weeks of being written — climbed noticeably as AI adoption grew.
Boilerplate, repetitive patterns, test scaffolding, documentation drafts for legacy systems, and learning unfamiliar APIs. Core architecture and security-critical logic still need experienced human judgment.
Better repo-level context will likely reduce duplication and pattern drift. It won't solve the ownership and institutional-knowledge gap, which is a process problem, not a model problem — a 2026 academic study on GenAI-induced technical debt found the core issue is developers deferring verification, not a lack of model capability.