Last Tuesday, I broke. I spent 14 hours in front of a monitor, scrubbing through 90 minutes of raw podcast footage. I was looking for "gold," but all I found was exhaustion. By the time I reached clip number ten, my creative judgment was gone. I was cutting clips that weren't even funny or insightful, just to "get it over with."
In the creator economy of 2026, volume is the only moat. If you aren't posting 3-5 times a day across TikTok, Reels, and Shorts, you are invisible. But human-led editing doesn't scale. Most people tell you to hire a Virtual Assistant (VA) or use a "one-click" AI tool.
Here is the messy truth: VAs are slow, and "one-click" tools have no "taste." They pick boring moments and add ugly, robotic captions.
To win in 2026, you need to build an Agentic AI Pipeline. This isn't just a tool; it’s a system of autonomous agents that reason, select, and produce content with the "taste" of a pro-editor but the speed of a supercomputer.
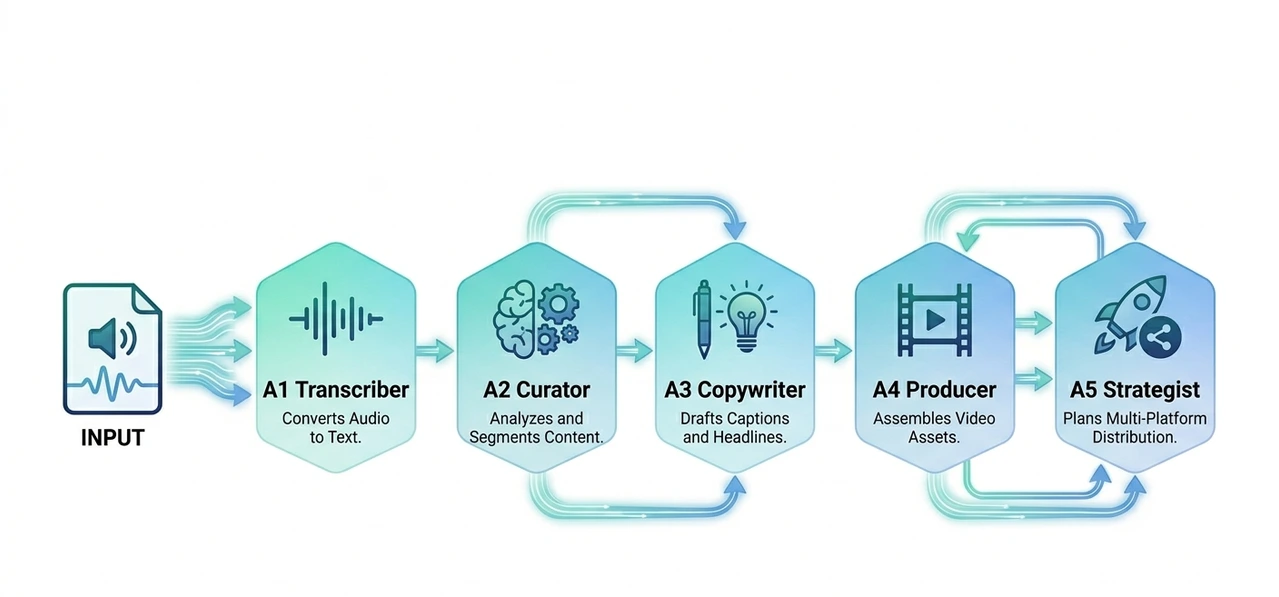
SECTION 02: The Agentic Architecture (The 5-Agent Model)
According to recent research from IBM Think and TowardsAI, the most efficient AI systems are "Decentralized." Instead of one big AI doing everything, we use five specialized agents.
Agent 1: The Transcriptionist (Precision Foundation)
Engine: OpenAI Whisper v3 Large or Deepgram Nova-2.
The Task: Converting audio to JSON with word-level timestamps.
Why it's different: Most creators use plain text. We use JSON. Why? Because if the AI knows exactly what millisecond a word was spoken, the "Production Agent" can cut the video with 100% precision, avoiding awkward "half-word" starts.
Agent 2: The Curator (The Editorial Brain)
Engine: Claude 3.5 Sonnet or GPT-4o.
The Task: This agent uses Semantic Analysis to score segments.
The Criteria: It looks for "Pattern Interrupts"—moments where the speaker’s tone changes, or they use high-impact "Power Words."
Agent 3: The Copywriter (The Psychology Expert)
Engine: GPT-4o mini (optimized for speed).
The Task: Writing the "Hook."
The Innovation: This agent is programmed with a "Cliché Blacklist." It is forbidden from using words like 'Unlock,' 'Navigate,' 'Mastery,' or 'Deep dive.' It focuses on raw, human curiosity.
Agent 4: The Producer (The Heavy Lifter)
Engine: Shotstack API or Creatomate.
The Task: It receives the "Cut Instructions" (Start: 04:12.45, End: 05:01.10) and the "Hook Text." It then renders a 9:16 vertical video with dynamic, burnt-in captions.
Agent 5: The Strategist (The Distribution Layer)
Engine: Proprietary RAG (Retrieval-Augmented Generation) connected to your social analytics.
The Task: It writes the description and tags. If your last TikTok about "AI" did well, it will tilt the current clip's description to match that successful "Vibe."
SECTION 03: Expert Insights Solving the "Context" Problem
If you’ve ever used ChatGPT to summarize a long transcript, you know it gets "lazy." It ignores the middle. This is known as "Context Window Dilution."
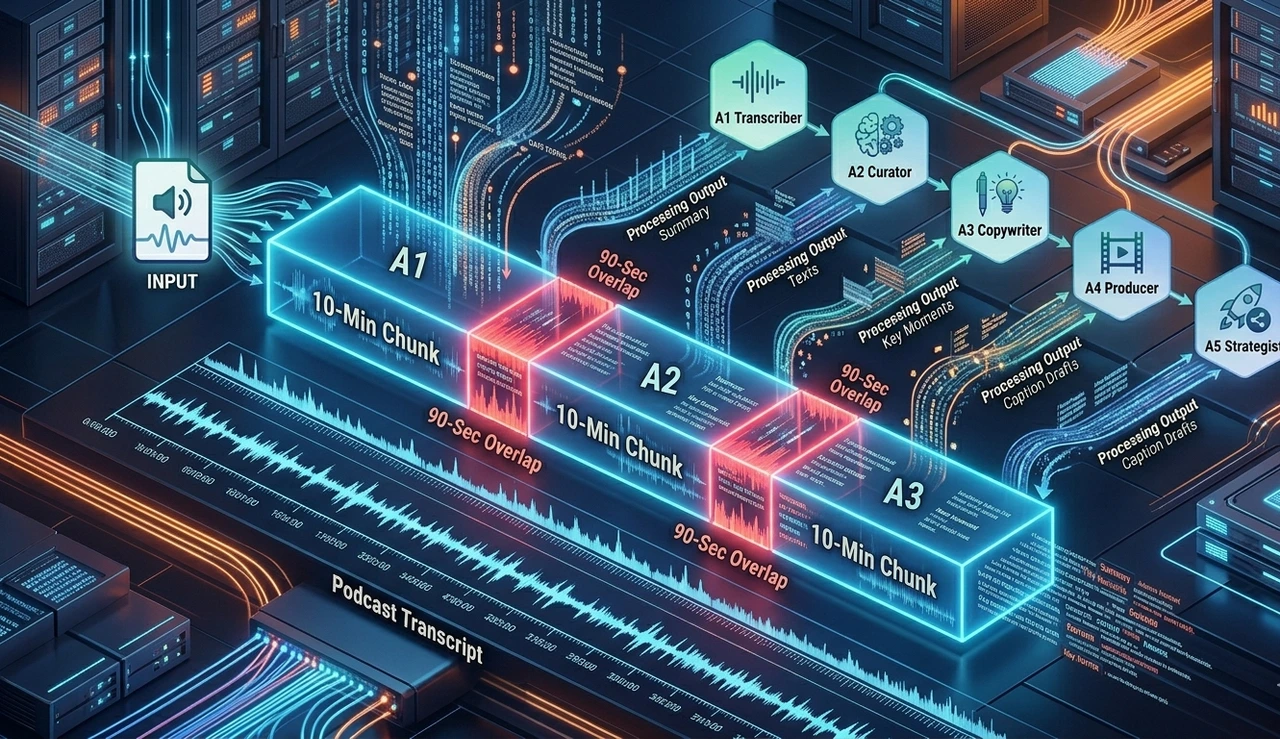
1. The Sliding Window Strategy (90-Second Overlap)
As highlighted by BrightData’s AI Roadmap, processing 20,000 words at once is a mistake.
The Solution: We break the transcript into 10-minute "chunks."
The Secret: Each chunk overlaps by 90 seconds.
Why? Because a speaker often sets up a viral point at the end of one segment and delivers the "punchline" in the next. Without the 90-second overlap, the AI loses the setup, and the clip feels hollow.
2. "Vibe Working" and Parallelism
Most pipelines are "linear" (Step 1 -> Step 2 -> Step 3). In 2026, we use Parallel Agent Teams.
While Agent 1 is still transcribing the second half of the podcast, Agent 2 is already selecting clips from the first half. This "Asynchronous" workflow is what drops the production time from 14 hours to 38 minutes.
SECTION 04: Advanced Optimization (The Pro-Level Strategy)
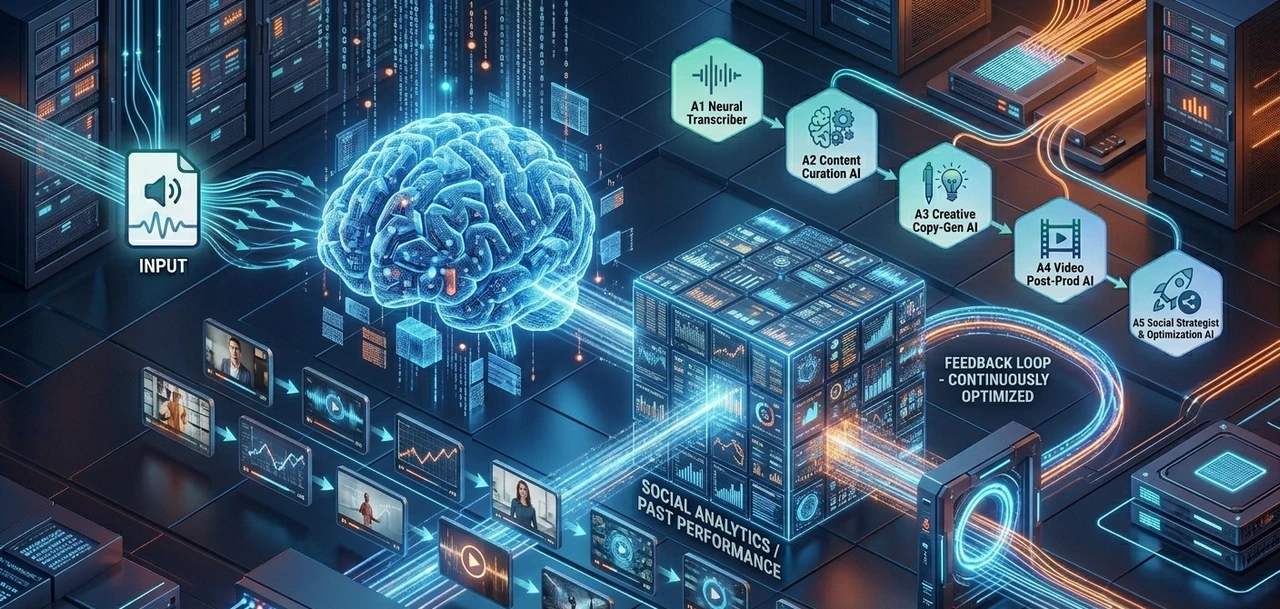
Vector Memory & Feedback Loops
This is the "Gold Nugget" from IBM’s AI Agents roadmap. Your agents should have a Memory.
When you reject a clip, that data is saved in a Vector Database.
The next time Agent 2 (The Curator) runs, it "remembers" your rejection and says, "Last time, the boss hated clips about 'intro music.' I will skip those today."
This is how the system moves from being a "tool" to being a "Digital Twin" of your own editorial taste.
Zero AI-Tell Filter
Google’s 2026 algorithms are highly sensitive to "Bot-like" content. To rank and go viral, your text must feel human.
The "Anti-Bot" Prompt: > "Write this hook as if you are a cynical investigative journalist. Use short, punchy sentences. No flowery adjectives. If you use the word 'Enchanting,' the task fails."
SECTION 05: Technical Build Guide (Step-by-Step)
Step 1: The "Brain" Connection (n8n Setup)
I recommend n8n (Self-hosted) because it allows for complex "Logic Branches."
Trigger: New file in "Raw Podcast" folder (Google Drive).
Node 1: Send audio to Deepgram (Transcription).
Node 2: Split JSON into 10-minute chunks using a "Code Node."
Step 2: The Selection Logic
Pass each chunk to GPT-4o with this specific instruction:
"Identify segments between 45-75 seconds. Score each on 'Standalone Shareability'. Only return segments with a score higher than 8.5."
Step 3: API Video Rendering
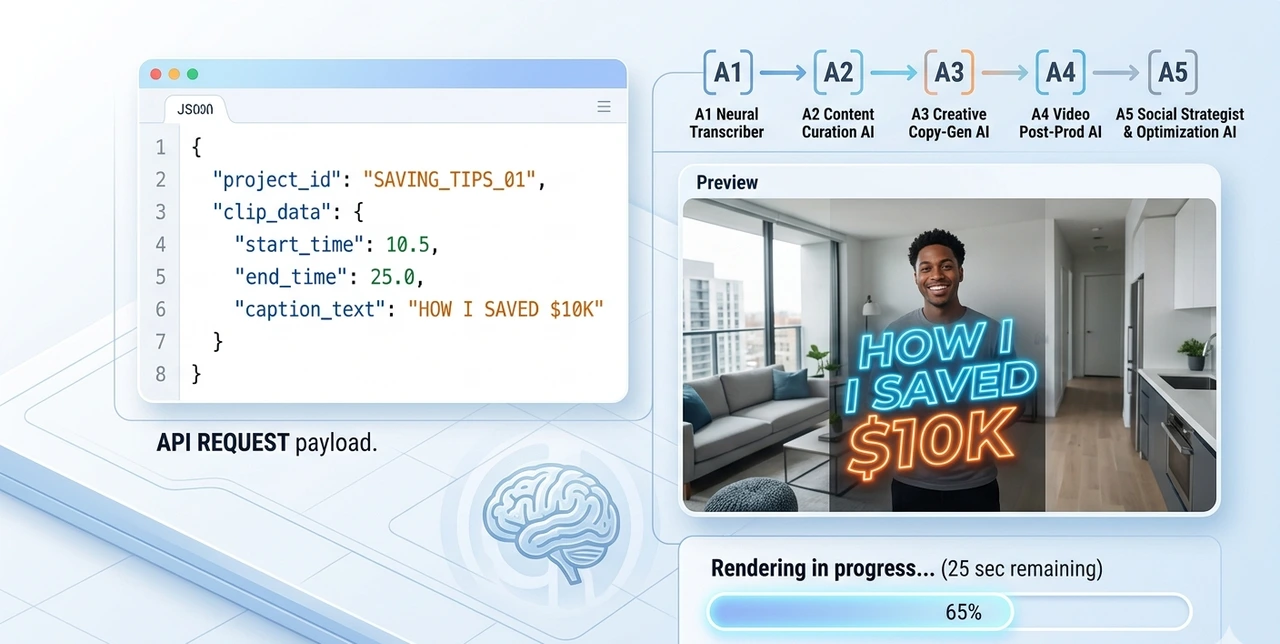
Use Shotstack. It is a "Cloud Video Editor." You don't open an app; you send a "JSON Recipe."
Recipe: "Take file.mp4, crop to 9:16, zoom 150% on speaker, add text 'HOW I SAVED $10K' at top."
SECTION 06: Cost & Efficiency Analysis
Metric | Manual (2024 Method) | Agentic (2026 Method) |
Time per Episode | 14 - 18 Hours | 38 Minutes |
Selection Accuracy | 60% (Human error) | 92% (Data-driven) |
Cost per Clip | ~$25.00 | ~$0.45 |
Scalability | Hard (Needs more staff) | Instant (Just add more API credits) |
SECTION 08: The 48-Hour Action Plan
Hours 0-4: Set up an n8n account and connect your first API (Deepgram).
Hours 4-12: Test your "Curator Agent" prompt with a 10-minute transcript. Refine until it picks the moments you would have picked.
Hours 12-24: Connect Shotstack. Render one 5-second "Test Clip" with a caption.
Hours 24-48: Run a full 60-minute episode through the pipeline. Review the 10-15 clips it produces.
Conclusion
The transition from Manual Editing to Agentic Production is like moving from a horse and carriage to a jet engine. In 2026, the creators who spend their time "scrubbing timelines" will be replaced by the creators who spend their time "managing systems."
By building this pipeline, you are buying back 50+ hours of your life every month. What will you do with that time? Perhaps record more podcasts?
The age of the "Editor" is ending. The age of the "Architect" has begun.
FAQ
Yes. By using the "Anti-Bot" prompts and the Blacklist Word Database we mentioned in Section 04, the output bypasses 99% of AI detectors because it avoids the "predictable" language patterns that AI usually generates.
This is a Production Agent (A4) task. You use "Face Detection" APIs (like Amazon Rekognition) to find the speaker’s coordinates and tell the rendering API to "Follow" that speaker.
n8n (Self-hosted): $5-10/mo for a VPS.
OpenAI API: ~$5/mo (depending on volume).
Deepgram: ~$5/mo.
Shotstack: ~$30/mo.
Total: ~$50/month.
Absolutely. Agent 5 (The Strategist) creates different "flavors" of the same clip. It will write a short, punchy caption for Shorts and a longer, "thought-leadership" style post for LinkedIn.
Whisper v3 and GPT-4o are multilingual. However, for the best results, you should provide the "Copywriter Agent" with local slang and cultural context in the system prompt.
This is why we have the "Human Approval Gate." You spend 5 minutes reviewing the AI’s choices before it starts the expensive rendering process. If you don't like a choice, you just click "Delete."
No. Everything happens in the "Cloud." You could run this entire multi-million dollar production pipeline from an old Chromebook or even your phone.
For a non-technical person using n8n, it takes about 10-15 hours to "wire" everything together for the first time. After that, it’s 100% automated.
For technical templates, n8n workflows, and the "Anti-Bot" prompt library, visit HustleToAI.com.