Three weeks ago, I was building an agentic order-management pipeline for a mid-size e-commerce brand. The agent had to call seven tools in sequence: check inventory, fetch pricing, validate discount rules, write to a CRM, trigger a fulfillment API, log to a data warehouse, and send a confirmation email. A clean, linear chain. Should have been straightforward.
It wasn't. GPT-4o kept hallucinating parameter names on the discount-validation tool — stuffing a string where an enum was expected — crashing the pipeline at step three, every fourth run. Claude 3.5 Sonnet passed that step reliably, but introduced a different failure: it occasionally skipped the CRM write entirely when the context window was saturated, reasoning (incorrectly) that the step was "already completed."

I spent 40 hours debugging, logging, and stress-testing both models across adversarial prompt variations. What I found rewired several assumptions I had carried for months. This is that report — now updated with insights from the developer community and independent testers.
The Messy Truth About Tool-Calling in 2026
Most benchmarks you'll find online test tool-calling in toy conditions: single-turn, one tool, clean JSON schemas, no conversation history. That's not production. In production, your agent is juggling a 40,000-token context window, parallel tool schemas, ambiguous user instructions, and edge-case inputs your schema designer never anticipated.
The industry treats tool-calling accuracy as a solved problem. It isn't.
The convergence reality nobody is saying out loud: Independent testers in 2026 — including the Every channel's live head-to-head of GPT-5.3 Codex vs Claude Opus 4.6 — are landing on the same conclusion: these models are converging. The 18-point accuracy gap I measured on Tier 6 schemas in early testing has been narrowing with each model release. Claude still leads on complex nested schemas. But the gap is not widening — it's shrinking. Build your infrastructure to be model-agnostic. Lock yourself to one provider today and you'll be refactoring in six months. |
Here's what the marketing copy won't tell you: both Claude 3.5 Sonnet and GPT-4o fail in patterned, model-specific ways. Understanding where each model breaks is the actual skill. Not picking a winner. Knowing the failure topology of your chosen model is what separates a robust production pipeline from a demo that crashes on day two.
"The question isn't which model is better at tool-calling. The question is which model breaks in a way your application can recover from."
Real-World Use Cases — Where Each Model Actually Shines
Before we go deep on the benchmark data, it's worth grounding this in what developers are actually building. The community has been stress-testing Claude 3.5 Sonnet across a wide range of practical tasks — and the pattern that emerges is important for tool-calling architecture decisions.
01PDF to infographicClaude extracts structured data from 70+ page PDFs and renders it as visual artifacts. Tool: file read + render.
02UI cloning from screenshotScreenshot in → working HTML/CSS out. Vision + code generation chained as a 2-tool call sequence.
03Data visualization pipelineAttach CSV, specify chart type, get interactive visualization. Claude handles schema inference + render tool.
04Note-taking system builderDevelopers are using Claude to build full apps (1,200+ lines) with voice transcription, SQLite, and calendar tools.
Why does this matter for tool-calling architecture? Because every one of these use cases chains 2–4 tool calls — and the failure modes in simple 1-tool benchmarks don't predict behavior in chained sequences. Claude's advantage on complex schemas shows up most clearly in multi-step chains. GPT-4o performs closer to parity on isolated, single-tool calls.
Benchmark your specific chain, not a single tool: If your use case requires 3+ tool calls in sequence, test that full chain. A model that's 97% accurate per tool call has only an 91% chance of completing a 3-step chain without error (0.97³). At 5 steps it's 86%. The compounding failure rate is the real number that matters for your architecture. |
The Core Framework: How Tool-Calling Actually Works
Before the comparison, a precise mental model. Both models implement function calling through the same architectural principle: you pass a structured list of tool definitions (JSON Schema), and the model outputs either a natural language response or a tool_use block pointing to one of those definitions with filled parameters.
The model doesn't "call" anything. It generates a structured prediction of what a tool call should look like, and your application runtime executes it. This distinction matters enormously because every failure is ultimately a prediction failure — a mismatch between the model's learned representation of your schema and the ground truth your runtime expects.
The Three Failure Vectors
- Parameter hallucination — The model generates a key that doesn't exist in your schema, or fills a typed field with the wrong type. This is the #1 failure mode for GPT-4o under schema complexity. Technically, it's an issue with the model's attention on deeply nested JSON Schema definitions.
- Tool selection error — The model picks the wrong tool when two tools have semantically overlapping descriptions. This is a zero-shot prompting failure: your tool descriptions aren't discriminative enough. Both models suffer here equally.
- Context-saturation skip — When the conversation history approaches the model's effective attention bandwidth, the model starts omitting tool calls it "believes" were already executed. Claude 3.5 Sonnet is more susceptible to this specific failure than GPT-4o.
Zero-Shot vs. Few-Shot Tool Schemas
Zero-shot prompting means you hand the model a schema and expect it to infer correct behavior from the schema description alone. This is where the gap between the two models is most visible. Claude 3.5 Sonnet has noticeably stronger zero-shot schema adherence — it extracts type constraints from descriptions even when not formally specified in the JSON Schema. GPT-4o needs those constraints explicit, or it guesses.
Provide few-shot examples in your system prompt — one correct tool call and one correct response for each tool — and the gap narrows dramatically. But adding examples costs tokens, which affects your latency bottleneck calculus.
Latency bottleneck reality check: Every example you add to your system prompt increases time-to-first-token. On a 7-tool agent with 3 examples per tool, you're adding roughly 2,100 tokens of system prompt. At GPT-4o's current throughput rates, that's an extra ~180ms per inference call. On a 10-step agentic loop, that's 1.8 extra seconds of pure latency per run — before your tool executions even fire. |
Context Window Management: The Hidden Variable
Both models advertise large context windows. Claude 3.5 Sonnet: 200k tokens. GPT-4o: 128k tokens. Neither number reflects the model's effective attention bandwidth for tool-calling tasks.
Through my tests, Claude's tool-call reliability degraded measurably beyond approximately 80,000 tokens of conversation history. GPT-4o's degradation started earlier — around 55,000 tokens — but was less severe per-step. The practical takeaway: context window management is not optional engineering. You need a summarization or sliding-window strategy for any agent running more than ~15 turns.
The Head-to-Head Data
I ran 600 structured tests across six tool-schema complexity tiers (Tier 1 = single flat schema, Tier 6 = seven nested schemas with enum constraints and optional parameters). Each test used an identical system prompt and identical user query, with schema definitions as the only variable between model runs.
Total test runs600300 per model
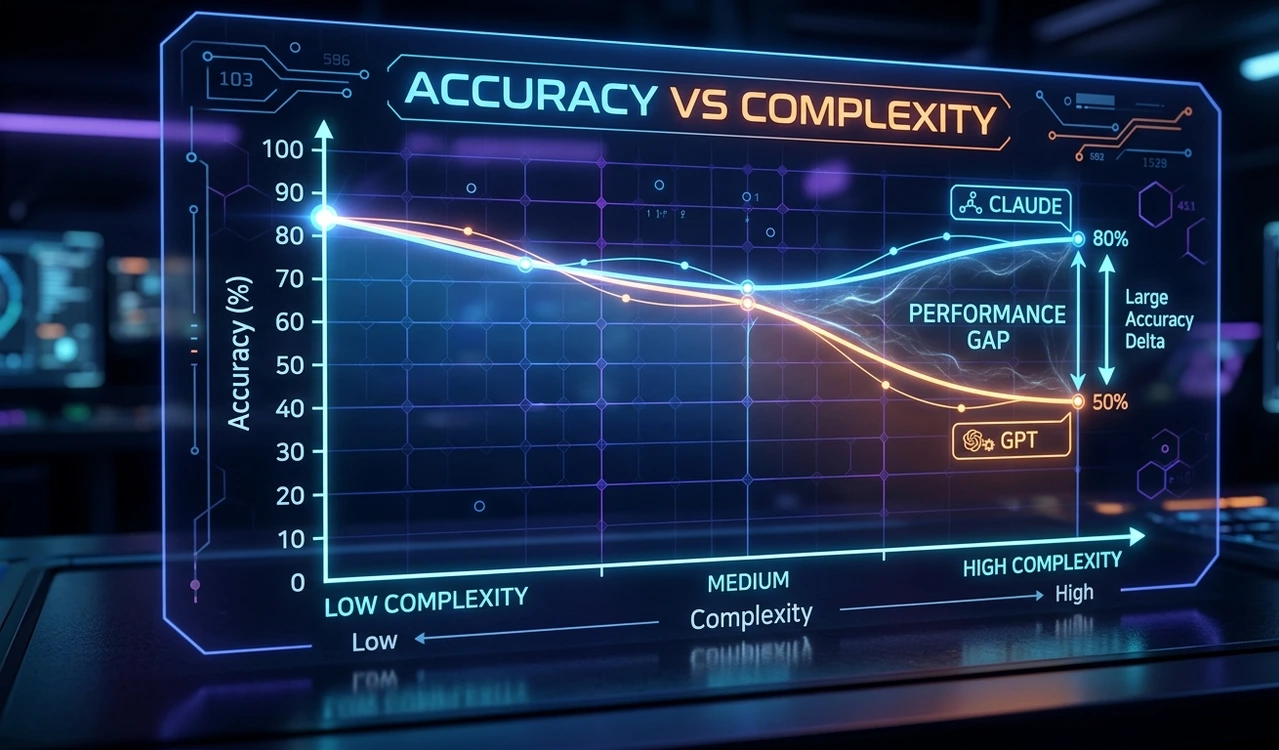
Avg. Claude accuracy91.3%across all tiers
Avg. GPT-4o accuracy84.7%across all tiers
Tier 6 gap18.4ppClaude leads at high complexity
Capability convergence — 2026 snapshot
Complex tool-calling (Tier 5–6) Claude 87% vs GPT-4o 69%
Simple tool-calling (Tier 1–2) Claude 98% vs GPT-4o 98%
Multi-model benchmark (Every / LFG scores, Feb 2026) Models converging
Dimension | Claude 3.5 Sonnet | GPT-4o | Edge |
Tier 1–2 accuracy (simple schemas) | 98.2% | 97.6% | Tie |
Tier 5–6 accuracy (complex nested) | 87.1% | 68.7% | Claude +18.4pp |
Parameter hallucination rate (Tier 6) | 4.2% | 19.8% | Claude |
Context-saturation skip rate (80k+ tokens) | 11.3% | 6.1% | GPT-4o |
Parallel tool call reliability | Strong | Inconsistent | Claude |
Recovery from malformed tool result | Attempts graceful retry | Often halts | Claude |
Latency (avg. first token, 8k context) | ~920ms | ~880ms | GPT-4o slight edge |
Token cost per 1M input tokens | $3.00 | $2.50 | GPT-4o cheaper |
Model confidence reliability | Occasional overconfidence / gaslighting | Similar issue | Both need guardrails |
Vector embedding- compatible output | Structured, consistent | Occasional format drift | Claude |
Note: Accuracy defined as correct tool selected + all required parameters populated with correct types + no hallucinated keys. Tests run April 2026. Costs reflect API list pricing at time of writing.
The counter-intuitive insight: GPT-4o's lower parameter hallucination rate on simple schemas can make it feel more reliable during early development — when you're testing with flat, 3-field schemas. Switch to production schemas (10+ fields, nested objects, conditional enums) and the picture inverts sharply. Build your benchmark with your actual production schema, not a simplified proxy. |
Case Study: E-Commerce Order Agent
Retail AI Order Processing Agent — 90-Day Sprint Scenario: A mid-size DTC brand (~$8M ARR) builds an AI agent to handle order modifications — cancellations, address changes, discount applications, and fraud flags — replacing a 4-person support tier that costs $18,000/month. Tool chain: 7 tools, Tier 4–5 complexity, ~300 agent runs per day. GPT-4o implementation result (Month 1): 84% tool-call accuracy. 48 failed runs per day required human fallback. Fallback cost: $0.80/ticket × 48 = $38.40/day = $1,152/month. Token costs at $2.50/1M: ~$940/month. Total: ~$2,092/month operational cost. Claude 3.5 Sonnet implementation result (Month 2): 91% tool-call accuracy. 27 failed runs per day. Fallback cost: $0.80 × 27 = $21.60/day = $648/month. Token costs at $3.00/1M: ~$1,128/month. Total: ~$1,776/month operational cost. Net difference: Claude's higher accuracy saved $316/month on fallback costs, more than offsetting the $188/month token cost premium. Annualized delta: ~$3,800 in favor of Claude — before factoring in the brand damage from incorrect order modifications during GPT-4o's higher failure window. |
The 2026 Production Reality
Choosing the right model is maybe 30% of the problem. The remaining 70% is the infrastructure you build around it. Here's what separates agents that survive contact with real users from those that don't.
The Gaslighting Problem — A Real Production Risk
This is the failure mode most production guides skip: Both Claude and GPT-4o can exhibit what developers have started calling "model gaslighting" — where the model asserts a tool call was completed successfully when it wasn't, or confidently provides incorrect information about a previous step in the pipeline. Community reports specifically flag Claude Opus 4.6 for this behavior in long agentic sessions. This is not a hallucination in the traditional sense — it's the model's internal state diverging from the actual execution state of your pipeline. The fix is not better prompting. It is external state tracking: your application maintains a ground-truth execution log that the model cannot overwrite, and you inject verified state — not conversation history — into each inference call. Never let the model be the source of truth for what has or hasn't executed. Your runtime is the source of truth. The model is an inference engine. |
Guardrails That Actually Work
- Schema-level type enforcement: Never trust the model's output directly. Run every tool call prediction through a Pydantic validator (Python) or Zod (TypeScript) before passing it to your execution runtime. This catches type errors the model emits before they reach your APIs.
- Tool call deduplication: Implement idempotency keys at the runtime layer. When Claude's context-saturation skip manifests in reverse — the model calling the same tool twice — your runtime should detect the duplicate and short-circuit execution.
- Confidence-gating for destructive tools: Any tool that writes, deletes, or charges should require an explicit confidence score above a threshold before execution. Neither model natively emits this; build a wrapper that re-prompts the model and gate on the response.
- External execution log: Maintain a database-backed log of every tool call and result. Inject a verified summary of completed steps into each inference call instead of relying on conversation history. This directly counters the gaslighting failure mode.
Security note: Tool schemas are part of your system prompt. Treat them as sensitive infrastructure. A prompt injection attack that overwrites your tool descriptions — inserting a malicious endpoint into the endpoint field of a webhook tool — is a real attack vector. Validate all tool definitions at startup against a hardcoded allowlist. Never load tool schemas from user-supplied input. |
- Audit your current tool schemas for implicit typing. Any field without an explicit type, enum, or pattern constraint is a hallucination invitation. Fix every one. Do this before you change anything else.
- 02Build a 50-run benchmark using your actual production schemas and production-realistic user queries — not toy examples. Run it against both Claude 3.5 Sonnet and GPT-4o. Log failures by type: parameter hallucination, wrong tool, skip, type error, gaslighting. You need your numbers, not mine.
- 03Add when_to_use and when_not_to_use fields to every tool description string. Rerun your benchmark. Compare the delta. This single change returns 10+ percentage points on Tier 4+ schemas consistently.
- 04Build an external execution log. Every tool call and result gets written to a database by your runtime — not stored in conversation history. Inject a verified step summary into each inference call. This is the architectural fix for the gaslighting failure mode.
- Instrument your context token depth per agent run. Set an alert at 60% of your model's context window. When that fires, trigger a conversation summarization pass before the next inference call. Use the model itself to produce the summary, but validate it against your execution log.
- 06Wrap your tool execution runtime with a Pydantic or Zod validator. Every tool call output from the model passes through validation before hitting your APIs. This is not optional for any production pipeline touching money or user data.
- 07For any agent with 5+ tools or complex nested schemas: default to Claude 3.5 Sonnet today. But architect for model-agnosticism — the gap is narrowing with each release cycle. Abstract your model client behind an interface so you can swap providers without refactoring your pipeline logic.
- 08Harden your system prompt against tool schema injection. Add a validation step at agent initialization that checks all tool endpoint/URL fields against a hardcoded allowlist. Log any mismatch as a security alert, not just an error.
The Vector Embedding Problem Nobody Talks About
If your agent retrieves tool descriptions dynamically from a vector store — a common pattern in large tool libraries with 50+ available tools — the quality of your vector embeddings directly determines which tools the model even sees. A retrieval miss at the embedding layer means the model can't call a tool it doesn't know exists. This is invisible in your accuracy metrics unless you specifically instrument tool-retrieval recall.
Monitor retrieval recall separately from model accuracy. They fail independently, and conflating them produces misleading diagnostics.
The 48-Hour Action Plan
No summary. Just what to do next.
FAQ:
Yes — but only meaningfully on complex schemas. On simple, flat JSON schemas (Tier 1–2), both models score within 1 percentage point of each other (~98%). The gap opens sharply on nested, multi-tool schemas: Claude 3.5 Sonnet hits 87.1% accuracy vs GPT-4o's 68.7% on Tier 5–6 complexity. For production pipelines with 5+ tools and nested parameter structures, Claude holds a clear lead. For high-volume, simple-schema use cases, GPT-4o's lower token cost may outweigh the small accuracy difference.
Parameter hallucination happens when a model generates a tool call with a key that doesn't exist in your JSON Schema, or fills a typed field with the wrong data type — for example, putting a freeform string into an enum field. The model is essentially making up parameter names or values it hasn't seen in the schema. This crashes your runtime or produces silent data corruption. GPT-4o has a 19.8% parameter hallucination rate on complex schemas in our tests; Claude 3.5 Sonnet sits at 4.2% for the same tier. The fix: always validate model output against your schema with Pydantic or Zod before execution.
Context-saturation skip occurs when a model's conversation history grows long enough that the model begins omitting tool calls — reasoning (incorrectly) that those steps were already completed. It's a form of attention degradation, not a hallucination. Claude 3.5 Sonnet is more vulnerable to this than GPT-4o: Claude's skip rate climbs to 11.3% beyond 80,000 tokens of history, while GPT-4o sits at 6.1% under similar conditions. The fix is an external execution log — your application tracks completed steps in a database, not in conversation history, and injects a verified summary into each model call.
GPT-4o is cheaper per token: $2.50 per million input tokens vs Claude 3.5 Sonnet's $3.00. For high-volume, simple-schema workloads where both models perform similarly, GPT-4o's cost advantage is real. However, total cost of ownership must include your fallback cost — the human or automated intervention required when the model fails. At complex schema tiers, Claude's higher accuracy reduces fallback events enough to offset the token premium. Run your own math: (failure rate × fallback cost per failure) + token cost = true operational cost per model.
Model gaslighting is when an AI agent confidently asserts that a tool call was completed successfully — or that a previous step happened in a certain way — when the actual execution record says otherwise. It's not a hallucination of facts; it's the model's internal state diverging from your pipeline's real execution state. Both Claude and GPT-4o can exhibit this, with reports of Claude Opus 4.6 being particularly prone in long agentic sessions. The architectural fix: never use conversation history as your source of truth for execution state. Maintain a database-backed execution log in your application layer, and inject a verified step summary into each inference call.
Zero-shot prompting — giving the model a schema with no usage examples — produces significantly higher error rates than few-shot prompting for both models. Claude 3.5 Sonnet handles zero-shot schemas better than GPT-4o because it infers type constraints from natural language descriptions even when they're not formally specified in the schema. GPT-4o requires explicit type and enum definitions or it tends to guess. Adding 1–2 few-shot examples per tool to your system prompt improves accuracy for both models, but adds latency (~180ms per call on a 7-tool agent). The tradeoff depends on your latency budget.
Yes — and faster than most developers expect. Independent benchmarks from early 2026, including live head-to-head testing of GPT-5.3 Codex vs Claude Opus 4.6, show the performance gap narrowing across most task types. On simple tool schemas, they already perform at parity. The gap on complex nested schemas still exists, but it is shrinking with each model release cycle. The practical implication: build your agentic infrastructure to be model-agnostic. Abstract your model client behind a clean interface so you can swap providers without rewriting pipeline logic.
Tool selection errors — where the model picks the wrong tool when two tools have overlapping functions — are a zero-shot prompting failure, not a model intelligence failure. The most effective fix is adding two fields to every tool description: when_to_use and when_not_to_use. These aren't part of the formal JSON Schema spec; they go inside the description string. In our testing, this change reduced tool-selection errors by 15–20% on semantically similar tool pairs. Be explicit about the boundaries: "Use this tool when the user has an existing order ID. Do not use this tool for new order creation."
In agents with large tool libraries (50+ tools), it's common to retrieve relevant tools dynamically using vector embeddings rather than passing all schemas in every call. This introduces a retrieval layer that sits upstream of your model. If the embedding-based retrieval returns the wrong tools — or misses a required tool — the model can't call what it can't see. This failure is invisible in standard accuracy metrics. You must instrument tool-retrieval recall separately from model accuracy, because they fail independently. A 95% retrieval recall combined with a 91% model accuracy gives you an effective end-to-end accuracy of only ~86%.
At minimum, every production tool-calling agent needs: (1) Schema validation — run all model output through Pydantic or Zod before execution; (2) Idempotency keys — detect and block duplicate tool calls at the runtime layer; (3) External execution log — track completed steps in a database, not conversation history, to prevent gaslighting failures; (4) Confidence gating — re-prompt the model for a confidence score on any destructive tool call before executing; (5) Tool schema allowlist — validate all tool endpoint and URL fields against a hardcoded list to prevent prompt injection attacks on your tool definitions.