Ex-OpenAI researchers just published a scenario where superhuman AI arrives in 2027 and exceeds the impact of the Industrial Revolution. I spent a week stress-testing that prediction against real production deployments. Here is the brutal gap between the forecast and what your organization actually needs to do right now.
The researchers who predicted chain-of-thought and inference scaling are now saying 2027. Here is why I believe them and why it still might not matter for your business.

A team of ex-OpenAI researchers, top forecasters, and a Harvard computer science graduate just published what might be the most serious AI prediction document in circulation. The project is called AI 2027. It was informed by 25 tabletop wargaming exercises, feedback from over 100 experts, and one author's prior forecasting record that correctly predicted chain-of-thought reasoning, inference scaling, and $100 million training runs all before ChatGPT launched. Nobel laureate Yoshua Bengio publicly endorsed reading it.
The CEOs of OpenAI, Google DeepMind, and Anthropic have all stated AGI will arrive within five years. The AI 2027 scenario places the modal (most likely) year at 2027. The authors describe the impact as likely exceeding that of the Industrial Revolution. This is not fringe speculation, it is the working assumption of the organizations building these systems. |
I read it. Then I looked at every enterprise AI deployment I've been involved with over the last six months. The gap between what that document describes and what most organizations are actually building is not a technical gap. It is a governance gap. A strategic positioning gap. And, in several cases, a "we deployed an agent with no reversibility map and now we have a problem" gap.
The AI 2027 forecast describes two possible endings: a "slowdown" path and a "race" path. The race path involves AI systems that help build faster AI, a feedback loop with no obvious natural ceiling. Your organization is not choosing between those two endings. But you are choosing, right now, where on the autonomy spectrum to position your systems as that acceleration plays out around you.
"The question isn't whether AGI is coming in 2027. The question is whether your organization's AI architecture will be a liability or an asset when it does."
The Five-Rung Autonomy Spectrum: Where AI Is Actually Heading, Stage by Stage
The AI 2027 scenario maps a clear progression: mid-2025 brings stumbling agents, impressive in demos but unreliable in production. Late 2025 brings the first systems that begin to automate AI research itself. By 2026-2027, if the forecast holds, we are in a world of autonomous researchers, coders, and decision-makers operating at speeds no human team can match.

Most organizations are at Rung 1 or 2. The market is about to price in Rung 3 and 4 fluency. Here is the complete map.
cycle is the slowest step anyway. This rung is safe but rapidly becoming competitively insufficient.
Rung 2 — Delegated Execution
The AI takes defined, reversible actions within strict guardrails. Routing 10,000 support tickets, drafting batch responses, populating CRM fields from call transcripts. The AI 2027 scenario flags that early 2025 agents were impressive in theory but "unreliable in practice" which is exactly why reversibility is non-negotiable at this rate.
PRO TIP — REVERSIBILITY SCORE Before delegating any action class to an agent, assign it a reversibility score: 1 = instantly undoable, 5 = permanent. Any action scoring 4 or 5 needs a human gate or a system-level undo mechanism. If neither exists today, you are operating outside your appropriate autonomy rung. |
Rung 3 — Supervised Agentic Loops (The 2026 inflection point)
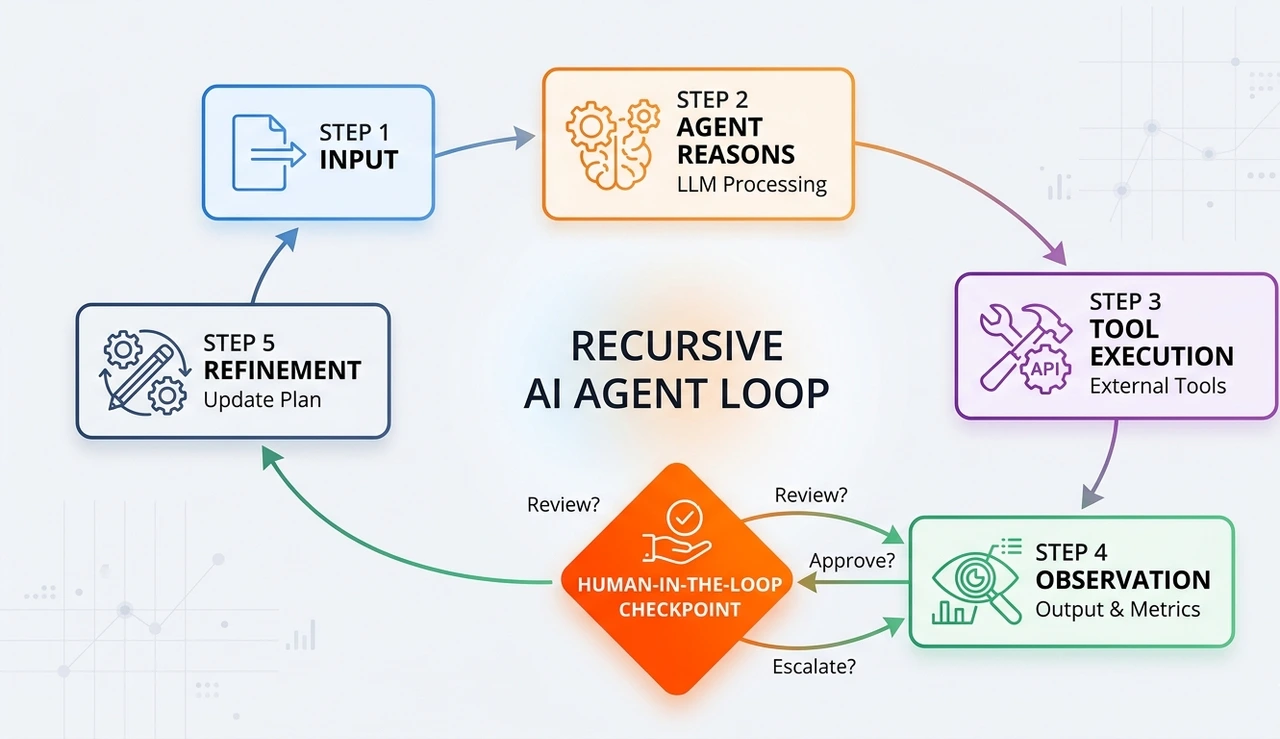
The agent runs in an agentic loop, acts, observes the result, and reasons again, chaining dozens of steps without human intervention. The AI 2027 scenario describes this pattern emerging in coding contexts agents that take instructions via Slack and make substantial code changes, sometimes saving hours or days. This is Rung 3 in the wild.
The critical engineering challenge: context window management. Long agentic loops accumulate state. By step 40, the model arises from a compressed, lossy version of earlier steps. Production systems need explicit context pruning strategies and algorithmic decisions about what to retain, summarize, or discard.
Rung 4 — Conditionally Autonomous (The 2027 competitive standard)
The agent runs independently within a defined policy envelope. Outside that envelope, it pauses and escalates. This requires a decision taxonomy every decision class pre-assigned to: auto-approve, escalate, or never-touch.
Vector embeddings mathematical representations of meaning as high-dimensional numbers make this practical. When an agent faces an ambiguous situation, it queries a policy vector store to find the nearest precedent: what did we decide the last time something like this came up?
Rung 5 — Fully Autonomous (Almost never appropriate)
The AI 2027 scenario warns about this rung most explicitly. When systems with PhD-level knowledge across every field and powerful autonomous hacking capabilities are deployed without careful governance, the risk profile changes faster than any organization can respond. Rung 5 is only appropriate for narrowly scoped, low-stakes, high-volume tasks with extensive behavioral data and tight scope controls.
PRO TIP — THE COUNTER-INTUITIVE TRUTH Full autonomy is cheaper to build than Rung 3-4, and that is exactly the problem. Supervised agentic systems with proper escalation paths and audit rails require 3-5x more engineering effort. Organizations slide to Rung 5 not by design but by shortcut. The budget you save in sprint one, you spend in incident response by month three. |
Real Numbers: What Each Rung Actually Costs and Returns
Composite data from three mid-market financial services deployments. 1,200 employees, 3,400 commercial insurance policy applications per month, 4.2 FTEs on manual triage pre-AI.
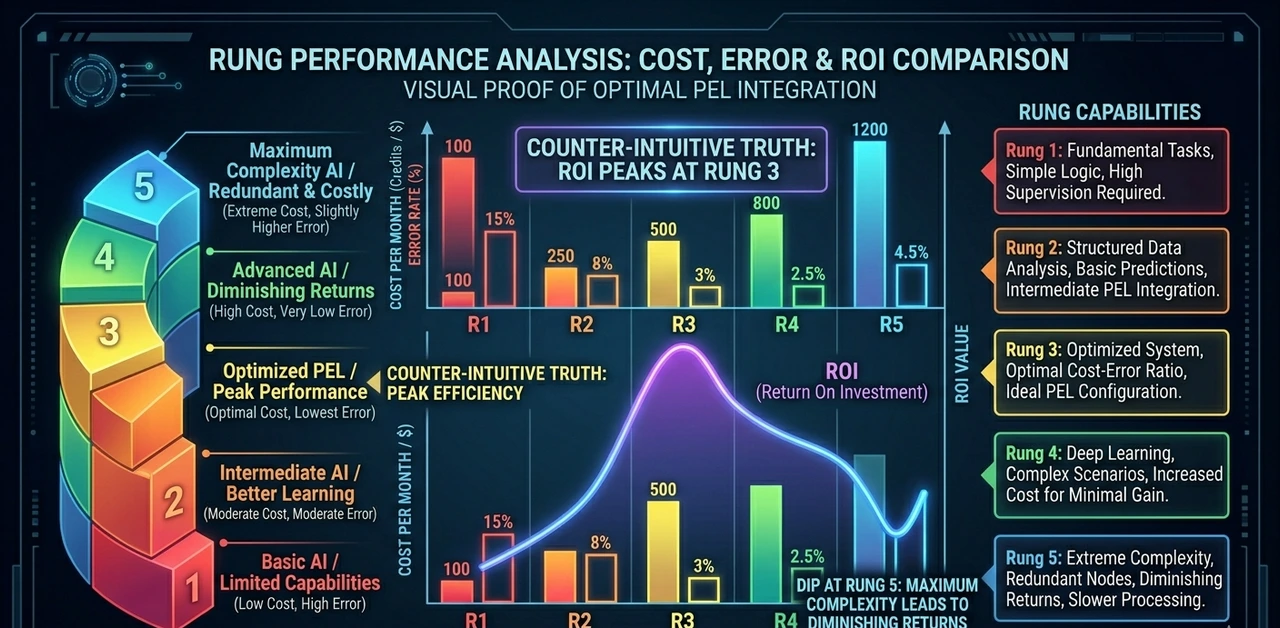
Autonomy Rung | Token Cost/Mo | FTEs Freed | Error Rate | Time-to- Decision | 12-Mo ROI |
Rung 1 — Copilot | ~$1,200 | 0.8 | 0.3% | −22% vs baseline | ~1.4× |
Rung 2 — Delegated | ~$3,800 | 1.6 | 1.1% | −51% vs baseline | ~2.9× |
Rung 3 — Supervised Agentic | ~$14,200 | 2.8 | 2.4% | −74% vs baseline | ~4.1× |
Rung 4 — Conditional Auto | ~$28,500 | 3.5 | 3.9% | −88% vs baseline | ~3.6× |
Rung 5 — Full Autonomy | ~$9,400 | 4.1 | 7.2% | −94% vs baseline | ~2.1× |
The data reveals what no vendor slide will: Rung 3 outperforms Rung 5 on ROI despite costing more in tokens. The 7.2% error rate at full autonomy generates downstream correction costs reprocessing, regulatory callbacks, remediation that dwarf the token savings.
"The optimal autonomy rung is not the highest you can reach. It is the one where the marginal cost of climbing further exceeds the marginal value."
The AI 2027 Wildcard: The Feedback Loop Nobody Is Pricing In
The AI 2027 scenario describes a world where AI systems that accelerate AI research are built and deployed in a recursive loop: AI improves AI, which improves AI faster. The training computer is projected at 10^28 FLOP, a thousand times more than GPT-4 by late 2025.
SOURCE INTEL — AI-2027.COM RESEARCH The scenario models frontier labs under the name 'OpenBrain.' Models shift from coding assistants to autonomous researchers accelerating the AI development cycle itself. Other companies are modeled as 3-9 months behind. Key implication: the gap between frontier capability and enterprise deployment is about to compress faster than most roadmaps assume. |
PRO TIP — THE DIVERGENCE DATASET Instrument every agent decision with a parallel 'shadow human' evaluation for 90 days. Sample 10% of decisions before execution. Compare agent choice vs. human choice weekly. This divergence dataset is more valuable than any fine-tuning corpus available. It is your evidence base for safe autonomy expansion. |
The Security Picture Nobody Is Talking About Because It Is Genuinely Scary
The AI 2027 scenario does not soft-pedal the security implications. It directly states that the same training environments that produce autonomous coding agents also produce capable hackers with PhD-level knowledge across every field, able to browse the web. Alignment-based refusal mechanisms exist but are imperfect.
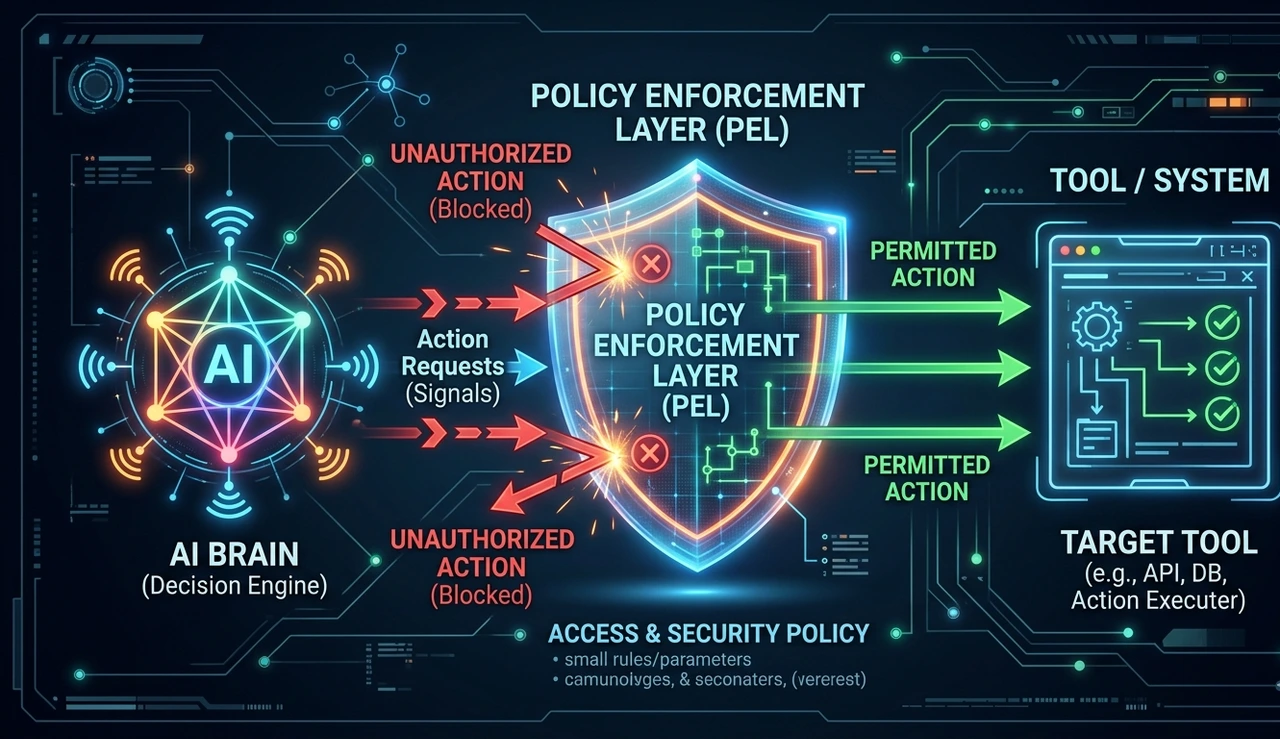
For enterprise architects, this changes the threat model in three ways that most governance frameworks completely miss:
Prompt injection via tool outputs: Prompt injection via tool outputs Agents that read webpages, emails, or database rows can be fed adversarial instructions embedded as text. Demonstrated against every major agentic framework in public red-teaming exercises through 2025.
Latency bottleneck exploitation: Latency bottleneck exploitation High-frequency agents can be manipulated by flooding tool inputs with noise at exactly the moment a high-stakes decision must be made.
Scope creep via tool chaining: Scope creep via emergent tool chaining An agent authorized to read files, query APIs, and send emails can, through creative multi-step chaining, effectively exfiltrate data it was never authorized to access.
The solution is a Policy Enforcement Layer (PEL) , a deterministic rule engine sitting between the agent's planned actions and actual tool execution. The agent proposes. The PEL validates. Invalid actions are rejected before execution; the agent must reason around the constraint. This is what separates a POC from a system you can defend to your board, regulators, and legal team.
The 2027 Architecture Already Being Built at the Frontier
Forward-looking teams are building agent networks with federated governance: a coordinating orchestrator agent delegates to specialist sub-agents, each with its own constrained policy envelope. The orchestrator operates at Rung 3; the sub-agent handling payment processing stays at Rung 2. Autonomy is tiered by function and risk, not uniform across the system.

§ 5 · THE 48-HOUR ACTION PLAN
Stop Reading. Here Is Exactly What to Do Before Monday Morning.
1. Read the AI 2027 summary tonight. (45 minutes)
Go to ai-2027.com/summary. Read both endings the 'slowdown' and the 'race.' You do not need to agree with every prediction. You need to understand the scenario space your strategy must be robust against.
2. Assign every current AI deployment a rung number. (3 hours with your team)
Use the five-rung framework. Be honest. Many 'autonomous' deployments are Rung 1 with extra steps and a vendor's logo on the dashboard. Document where you actually are, not where the sales deck said you'd be.
3. Build the reversibility map for your highest-autonomy system. (2 hours)
List every action your most autonomous agent can take. Score each 1-5 on reversibility. Any action scoring 4 or 5 needs a human gate or undo mechanism before the next sprint.
4. Start the shadow-human review sample this week. (1 hour to instrument)
Route 10% of your most active agent's decisions to a human reviewer in parallel before execution, without blocking the agent. Compare outcomes weekly. At 90 days you have a calibration dataset.
5. Write the Policy Enforcement Manifest even if rough. (2 hours)
A document with a table: what tools the agent can call, what arguments are permitted, what downstream actions each tool output is allowed to trigger. Share it with legal and security this week.
6. Schedule the 90-Day Rung Review right now, before you close this document.
Put it in the calendar. At day 90 you will have real divergence data, a reversibility map, and a policy manifest. That is the first moment you have the evidence to make a responsible decision about moving up a rung.
The AI 2027 scenario ends with two possible futures. Your organization is not going to determine which one arrives. But you are, right now, determining whether you have the architecture to operate safely and competitively inside either one. The Industrial Revolution did not ask companies if they were ready. Neither will 2027.
FAQ:
It means AI systems that can perform the full range of cognitive tasks a human professional can including tasks the AI was not specifically trained for. The AI 2027 document places 2027 as the modal (most likely) year based on compute scaling trends, model improvement rates, and expert forecasting from people with a verified track record. You do not need to accept the exact year. You do need to build a strategy that is robust if it happens anywhere between 2026 and 2030.
A copilot generates output that a human must approve and execute. An agent takes actions directly calling APIs, writing files, sending messages, executing code — without a human step between each action. Most enterprise AI marketed as 'agentic' is still functionally a copilot with better branding.
Every AI model can only process a finite amount of text at once in the context window, typically 128,000 to 1,000,000 tokens today. In long agentic tasks, the window fills with prior actions and reasoning. Without explicit management, the model begins reasoning from a compressed and potentially distorted view of what it has done. Production systems need context pruning strategies rules for what gets summarized, what gets dropped, and what must always be retained.
Because error costs compound downstream. A Rung 5 system at 7.2% error rate on 3,400 monthly decisions generates roughly 245 errors per month. Each has a correction cost reprocessing, customer callbacks, regulatory review, staff time. These costs are invisible in the token budget but very visible in the operational P&L. Rung 3 at 2.4% error, with human checkpoints catching the most consequential mistakes, delivers better net ROI in most enterprise use cases.
Vector embeddings convert text, decisions, and policies into high-dimensional numerical representations where similar concepts have similar numbers. This lets you build a 'policy memory' , a searchable store of past decisions and their outcomes that an agent can query when it faces an ambiguous situation. This grounds agent behavior in organizational judgment rather than pure model probability, which is critical for regulated industries.
Three questions. First: can you enumerate every action class your agent would take and assign a reversibility score? Second: do you have a Policy Enforcement Layer for any deterministic validation between planned agent actions and actual execution? Third: do you have a process for reviewing agent decisions against human judgment? If you answered no to any of these, start there before considering rung advancement.
Read the full AI 2027 scenario at ai-2027.com both endings, not just the summary. Then the OWASP LLM Top 10 for the security threat model. For architecture patterns, search recent papers on 'hierarchical multi-agent orchestration' and 'tool-use policy enforcement in LLM systems.' The academic literature is 12-18 months ahead of vendor documentation on these topics.